
دسته بندی ها: دستهبندی نشده
پوشش خبری شبکه 3 سیما از طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
پوشش خبری شبکه تهران صدا و سیما از طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
پوشش خبری شبکه تهران صدا و سیما از معرفی طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی با عنوان سیستم مدیریت یکپارچه فرآیند های کسب و کار IBPMS توسط میلاد شفیعیان مدیرعامل شرکت سامانه گستر هوشمند پویا
پوشش خبری شبکه تهران صدا و سیما از طرح برتر (IBPMS) در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
پوشش خبری شبکه 3 سیما از طرح برتر (IBPMS) در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
معرفی طرح برتر (IBPMS) در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
معرفی طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
معرفی سیستم یکپارچه مدیریت فرآیند های کسب و کار IBPMS به عنوان طرح برتر ملی در نخستین رویداد IRAN AI+ خانه هوش ایران توسط میلاد شفیعیان مدیر عامل شرکت سامانه گستر هوشمند پویا
معرفی طرح برتر (شرکت سامانه گستر هوشمند پویا) در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
پوشش خبری شبکه تهران صدا و سیما (شرکت سامانه گستر هوشمند پویا) از طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
پوشش خبری شبکه سه صدا و سیما (شرکت سامانه گستر هوشمند پویا) از طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
اهدای جایزه طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی به میلاد شفیعیان مدیرعامل شرکت سامانه گستر هوشمند پویا
در نخستین رویداد ملی هوش مصنوعی میلاد شفیعیان مدیر عامل شرکت سامانه گستر هوشمند پویا موفق به دریافت جایزه طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی گردید
این رویداد توسط خانه هوش ایران با حمایت دانشگاه شهید بهشتی و سایر ارگان ها و دانشگاه ها برای اولین بار در ایران برگزار شد






اهدای جایزه طرح برتر در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی به میلاد شفیعیان مدیرعامل شرکت سامانه گستر هوشمند پویا
پوشش خبری شبکه تهران صدا و سیما از طرح برتر نرم افزار IBPMS شرکت سامانه گستر هوشمند پویا در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
پوشش خبری شبکه سه سیما از طرح برتر نرم افزار IBPMS شرکت سامانه گستر هوشمند پویا در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
معرفی طرح برتر نرم افزار IBPMS شرکت سامانه گستر هوشمند پویا در نخستین رویداد ملی ایده های نوآورانه در هوش مصنوعی
مشاهده مقاله پویانا AI
مشاهده مقاله BPMS چیست؟
مشاهده مقاله EPMS چیست؟
مشاهده مقاله AML چیست؟
سوالات متداول ASP.Net Core
مزایای استفاده از CQRS در پروژه هایASP.net core
استفاده از الگوی CQRS (Command Query Responsibility Segregation) در پروژههای .NET Core دارای مزایای متعددی است، به خصوص در سیستمهای پیچیده و مقیاسپذیر. برخی از این مزایا عبارتند از:
- تفکیک وظایف (Separation of Concerns)
CQRSاصل جداسازی مسئولیتها بین عملیاتهای خواندن (Query) و عملیاتهای نوشتن (Command) را اعمال میکند. این کار باعث میشود که منطق بیزینسی مرتبط با هر عملیات بهتر سازماندهی شود و کد تمیزتر و قابل نگهداریتر باشد.
- مقیاسپذیری (Scalability)
با جدا کردن عملیاتهای خواندن و نوشتن، شما میتوانید آنها را به طور مستقل مقیاس دهید. به عنوان مثال، عملیاتهای خواندن را میتوان با استفاده از کش یا دیتابیسهای بهینهشده برای خواندن (Read-Optimized Databases) بهینهسازی کرد، در حالی که عملیاتهای نوشتن به طور مستقل مدیریت و مقیاسپذیر میشوند.
- بهبود کارایی (Performance Optimization)
عملیاتهای خواندن و نوشتن ممکن است نیازهای متفاوتی داشته باشند. با جداسازی آنها، میتوان منطق خواندن داده را برای بهبود عملکرد و پاسخدهی سریعتر بهینه کرد، مثلاً با استفاده از نماهای بهینهشده یا کش کردن دادهها.
- پشتیبانی بهتر از رویدادها (Event-Driven Architecture)
CQRSاغلب با Event Sourcing ترکیب میشود، که به شما این امکان را میدهد تا هر تغییری در سیستم را به صورت رویداد ذخیره کنید. این رویدادها میتوانند برای ارسال پیامها به سایر بخشهای سیستم یا برای پیگیری تاریخی کامل تغییرات استفاده شوند.
- نگهداری سادهتر و مقیاسپذیری پایگاهداده
با استفاده از پایگاه دادههای مجزا برای خواندن و نوشتن، میتوان حجم کار را بین چندین دیتابیس تقسیم کرد. این موضوع به بهبود عملکرد و همچنین مدیریت تراکنشها و قفلها در دیتابیس کمک میکند.
- امنیت بهتر
از آنجا که دسترسی به عملیاتهای نوشتن و خواندن به صورت جداگانه کنترل میشود، میتوان به راحتی سطوح مختلف امنیت و اعتبارسنجی را اعمال کرد. به عنوان مثال، ممکن است کاربران فقط مجوز خواندن داشته باشند و برخی فقط مجوز نوشتن.
- انعطافپذیری در تغییرات
با جدا کردن خواندن و نوشتن، تغییرات در یک قسمت (مثلاً افزودن فیچر جدید به قسمت خواندن) بر دیگری تأثیر نمیگذارد. این موضوع به انعطافپذیری بیشتر و کاهش هزینههای توسعه و نگهداری منجر میشود.
- استفاده مؤثرتر از DDD (Domain-Driven Design)
CQRSبه طور طبیعی با اصول طراحی Domain-Driven Design همخوانی دارد، زیرا اجازه میدهد منطق پیچیده بیزینسی (Commands) را از مدلهای خواندن سادهتر (Queries) جدا کنیم و این کار به توسعهدهنده کمک میکند تا با استفاده از الگوی مناسب برای هر کدام، کارایی و خوانایی را افزایش دهد.
- بهبود تستپذیری
با جداسازی عملیاتها، تست واحد و یکپارچهسازی آسانتر میشود. شما میتوانید هر بخش از سیستم را جداگانه تست کنید، که این موضوع به کیفیت بالاتر کد کمک میکند.
- سازگاری با میکروسرویسها
الگوی CQRS به خوبی با معماری میکروسرویسها ترکیب میشود. هر میکروسرویس میتواند عملیاتهای خواندن و نوشتن خود را جدا کرده و به طور مستقل مدیریت کند، که این موضوع به جداسازی منطقی بین سرویسها و مقیاسپذیری کمک میکند.
نتیجهگیری
استفاده از CQRS در پروژههای .NET Core به شما کمک میکند تا پیچیدگیهای سیستم را بهتر مدیریت کنید، مقیاسپذیری و کارایی را افزایش دهید و از معماری رویدادمحور و طراحی دامنهمحور بهره ببرید. البته باید توجه داشت که این الگو برای سیستمهای پیچیده مناسبتر است و ممکن است در پروژههای کوچک و ساده، اضافه کردن پیچیدگی غیرضروری باشد.
مزایای استفاده از unit test با xunit در پروژه های ASP.Net Core
استفاده از Unit Test با xUnit در پروژههای .NET Core دارای مزایای متعددی است که به بهبود کیفیت، قابلیت نگهداری، و توسعه پروژه کمک میکند. در ادامه برخی از این مزایا را بررسی میکنیم:
- بهبود کیفیت کد (Code Quality)
Unit Test به شما کمک میکند تا بخشهای مختلف برنامه خود را تست کنید و اطمینان حاصل کنید که هر بخش از کد به درستی کار میکند. xUnit به عنوان یکی از محبوبترین فریمورکهای تست، امکانات مختلفی را برای نوشتن تستهای باکیفیت فراهم میکند.
- تشخیص زودهنگام باگها
با اجرای تستهای واحد به صورت مداوم، میتوان باگها و خطاهای برنامه را در مراحل اولیه توسعه شناسایی و رفع کرد. این امر باعث میشود مشکلات بزرگتر و پیچیدهتر به حداقل برسند.
- ایجاد اعتماد در تغییرات (Confidence in Refactoring)
زمانی که تستهای واحد قوی و پوششدهنده دارید، میتوانید با اعتماد بیشتری کدهای خود را تغییر دهید یا بازآرایی کنید. اگر تغییری باعث بروز مشکل در یک بخش از کد شود، تستها به سرعت آن را نشان خواهند داد.
- قابلیت نگهداری و توسعه آسانتر (Maintainability)
پروژههای بزرگتر به مرور زمان پیچیدهتر میشوند. وجود تستهای واحد جامع به شما کمک میکند که تغییرات بعدی در کد را با اطمینان بیشتری انجام دهید و به طور مستمر از سلامت سیستم اطمینان حاصل کنید.
- پوشش تست (Test Coverage)
xUnit امکان سنجش میزان پوشش تستها را فراهم میکند، که این امر به توسعهدهنده کمک میکند بفهمد که چه بخشهایی از کد تست نشده و نیاز به پوشش بیشتر دارد.
- پشتیبانی از الگوهای مختلف تست
xUnit از تستهای دادهمحور، تستهای تئوری، و موارد مشابه پشتیبانی میکند که به شما اجازه میدهد تستهای متنوعتری بنویسید. این فریمورک به توسعهدهندهها این امکان را میدهد که از پارامترهای مختلف در تستها استفاده کنند و پوشش بهتری داشته باشند.
- همخوانی با ابزارهای مدرن
xUnit به طور کامل با ابزارهای مدرن .NET Core مانند Moq برای mocking، AutoMapper (برای تست مپینگها) و WebApplicationFactory برای تست API یکپارچه است. این ویژگیها به شما کمک میکنند تا تستهای جامعتری بنویسید که تمام جنبههای پروژه را دربر بگیرند.
- پشتیبانی قوی از Dependency Injection (DI)
xUnit امکان استفاده از Dependency Injection را برای ایجاد وابستگیهای مختلف در تستها فراهم میکند. به راحتی میتوان وابستگیهای خارجی را mock یا جایگزین کرد و تستهای واحد بدون اتصال به منابع خارجی (مانند پایگاه داده یا سرویسهای خارجی) نوشت.
- تستهای سبک و سریع
xUnit سبک و سریع است و به توسعهدهنده این امکان را میدهد که تستهای واحد به سرعت اجرا شوند. این ویژگی در پروژههای بزرگ که تعداد زیادی تست دارند بسیار مفید است، چرا که اجرای سریع تستها در زمان توسعه اهمیت بالایی دارد.
- قابلیت یکپارچهسازی با CI/CD
xUnit به راحتی با سیستمهای Continuous Integration/Continuous Deployment مانند Azure DevOps، GitHub Actions و Jenkins یکپارچه میشود. این ویژگی امکان اجرای خودکار تستها در هر مرحله از توسعه و قبل از استقرار در محیطهای تولیدی را فراهم میکند.
- انعطافپذیری و توسعهپذیری
xUnit به دلیل طراحی ماژولار و انعطافپذیری بالای خود، به راحتی قابل توسعه و سفارشیسازی است. شما میتوانید انواع شخصیسازیها مانند سفارشی کردن setup و teardown، مدیریت دادههای تست، و ایجاد متدهای تست سفارشی را در آن پیادهسازی کنید.
- پشتیبانی قوی از TDD (Test-Driven Development)
xUnit به خوبی از رویکرد توسعه مبتنی بر تست (TDD) پشتیبانی میکند. این فریمورک امکان نوشتن تستها پیش از کدنویسی اصلی را فراهم میکند و توسعهدهنده را تشویق میکند که ابتدا تست بنویسد و سپس کد را برای برآورده کردن آن تستها توسعه دهد.
نتیجهگیری
استفاده از xUnit برای Unit Test در پروژههای .NET Core مزایای بسیاری از جمله بهبود کیفیت کد، تشخیص سریع باگها، افزایش اعتماد در بازآرایی کد، و امکان یکپارچهسازی با ابزارهای مدرن توسعه را فراهم میکند. این فریمورک به دلیل طراحی ساده و انعطافپذیری بالا یکی از بهترین انتخابها برای توسعهدهندگان .NET محسوب میشود.
مزایای استفاده از carter در پروژه های ASP.Net Core
Carter یک کتابخانه سبک برای ایجاد API های RESTful در پروژههای .NET Core است که بر اساس ASP.NET Core ساخته شده و امکاناتی برای سادهسازی توسعه APIها ارائه میدهد. استفاده از Carter در پروژههای .NET Core دارای مزایای متعددی است که برخی از آنها عبارتند از:
- سادگی و مینیمالیسم
Carter به دلیل طراحی مینیمال خود، کار را برای توسعهدهندگانی که به دنبال یک راهحل سبک برای ساخت API هستند، ساده میکند. این کتابخانه نیازی به استفاده از قالبها و ابزارهای پیچیده ندارد و میتوان به سرعت APIها را توسعه داد.
- پشتیبانی از رویکرد ماژولار
Carter به شما امکان میدهد تا به سادگی روترها (Routes) را در قالب ماژولهای جداگانه سازماندهی کنید. این کار ساختار کد را تمیزتر و قابل نگهداریتر میکند. با استفاده از این ویژگی، هر ماژول به صورت مجزا عمل میکند و مسئولیت مدیریت مسیرها و منطق مرتبط با یک بخش خاص از API را دارد.
- سازگاری با ASP.NET Core Middleware
Carter به طور کامل با Middlewareهای ASP.NET Core سازگار است. این یعنی شما میتوانید از همه قابلیتهای ASP.NET Core مانند فیلترها، میانافزارها (middleware)، و سایر ویژگیها در کنار Carter استفاده کنید، بدون اینکه نیاز به پیادهسازی دوباره داشته باشید.
- بدون نیاز به Controller
برخلاف رویکرد سنتی ASP.NET Core که از کنترلرها استفاده میکند، Carter با حذف نیاز به کنترلرها، به توسعهدهندگان اجازه میدهد که از طریق ماژولهای سادهتر و منعطفتر APIها را ایجاد کنند. این کار منجر به کاهش پیچیدگی و افزایش سرعت توسعه میشود.
- استفاده آسان از مسیردهی (Routing)
Carter از مسیردهی (Routing) ساده و خوانا استفاده میکند که با سینتکس روشنی تعریف میشود. این ویژگی به کاهش کد اضافی کمک کرده و کار را برای توسعهدهندگان آسانتر میکند. شما میتوانید به راحتی مسیرها را تعریف کرده و به درخواستهای GET، POST، PUT و DELETE پاسخ دهید.
- پشتیبانی از مدل Binding و Validation
Carter امکان model binding و validation را به صورت پیشفرض فراهم میکند. شما میتوانید مدلها را به راحتی از درخواستها دریافت کرده و آنها را اعتبارسنجی کنید، که این امر فرآیند کار با دادههای ورودی کاربر را بسیار سادهتر و ایمنتر میکند.
- پشتیبانی از Dependency Injection (DI)
Carter به طور کامل از Dependency Injection در ASP.NET Core پشتیبانی میکند. این ویژگی به توسعهدهندگان امکان میدهد تا وابستگیها را به راحتی در ماژولها وارد (Inject) کرده و آنها را مدیریت کنند. این امر توسعهپذیری و نگهداری کد را بهبود میبخشد.
- همخوانی با تکنولوژیهای مدرن و ابزارهای جانبی
Carter به خوبی با ابزارهای مدرن مانند Swagger برای مستندسازی APIها، FluentValidation (برای اعتبارسنجی دادهها) و MediatR برای پیادهسازی CQRS سازگار است. این یکپارچگی به شما کمک میکند تا APIهایی مدرن و مقیاسپذیر ایجاد کنید.
- توسعه سریعتر و کارآمدتر
یکی از اهداف اصلی Carter سادهسازی فرآیند توسعه API است. به دلیل اینکه نیازی به پیادهسازی پیچیده کنترلرها یا بسیاری از الگوهای پیچیده دیگر نیست، توسعهدهندگان میتوانند با سرعت بیشتری پروژهها را پیادهسازی و تحویل دهند.
- کاهش کد اضافی (Boilerplate)
Carter به شدت بر کاهش کدهای اضافی تمرکز دارد. در بسیاری از پروژههای سنتی ASP.NET Core، باید کدهای زیادی برای کنترلرها و مسیرها بنویسید. Carter این پیچیدگی را کاهش میدهد و اجازه میدهد تمرکز اصلی روی منطق بیزینسی باشد.
- پشتیبانی از ویژگیهای پیشرفته ASP.NET Core
با اینکه Carter مینیمال است، اما همچنان از ویژگیهای پیشرفته ASP.NET Core مانند ModelState، Filters، و Authentication پشتیبانی میکند. این یعنی شما همچنان میتوانید از امکانات قدرتمند ASP.NET Core استفاده کنید، ولی با سادگی بیشتر در کدنویسی.
- توسعه APIهای تمیز و خوانا
Carter به توسعهدهندگان کمک میکند تا APIهایی تمیزتر و خواناتر بنویسند. ساختار ماژولار و روشهای ساده مسیردهی به این امر کمک میکند که کدهای API به راحتی قابل خواندن و نگهداری باشند.
- پشتیبانی از تستپذیری (Testability)
به دلیل استفاده Carter از رویکرد ماژولار و سادگی در تعریف مسیردهی و منطق، تست کردن کدها Unit Test و Integration Test بسیار سادهتر است. این کار باعث میشود که نوشتن تستهای خودکار برای APIهای توسعهیافته با Carter به راحتی انجام شود.
نتیجهگیری
Carter یک کتابخانه بسیار سبک و مینیمال برای توسعه APIهای RESTful در پروژههای .NET Core است. این ابزار به توسعهدهندگان اجازه میدهد که با سادگی بیشتر و کدنویسی کمتر، APIهای قدرتمندی ایجاد کنند. از مزایای کلیدی Carter میتوان به سادگی، انعطافپذیری، سازگاری با ASP.NET Core، کاهش کدهای اضافی و تستپذیری بالا اشاره کرد.
مزایای استفاده از .Net 8
استفاده از .NET 8 در پروژههای توسعه نرمافزار دارای مزایای بسیاری است که در ادامه به برخی از مهمترین آنها اشاره میشود:
- بهبود عملکرد (Performance Improvements)
.NET 8 شامل بهبودهای چشمگیری در زمینه عملکرد است، که باعث اجرای سریعتر برنامهها و بهینهتر شدن مدیریت منابع میشود. این بهبودها شامل بهینهسازیهای داخلی در JIT Compiler، Garbage Collection و Threading میباشد که به طور کلی سرعت و کارایی برنامهها را افزایش میدهند.
- پشتیبانی گستردهتر از WebAssembly و Blazor
.NET 8 پشتیبانی بهتری از Blazor WebAssembly ارائه میدهد، که به توسعهدهندگان اجازه میدهد اپلیکیشنهای تکصفحهای (SPA) با استفاده از C# و بدون نیاز به JavaScript ایجاد کنند. این قابلیت با بهبود عملکرد WebAssembly، کاهش زمان بارگذاری، و بهبود تجربه کاربری همراه است.
- هوش مصنوعی و یادگیری ماشین (AI & ML)
.NET 8 از ویژگیهای پیشرفته برای ادغام هوش مصنوعی و یادگیری ماشین پشتیبانی میکند. ابزارهای پیشرفتهای مانندML.NET و ONNX Runtime بهبود یافتهاند تا به توسعهدهندگان کمک کنند مدلهای یادگیری ماشین را در پروژههای خود به راحتی ادغام و استفاده کنند.
- پشتیبانی از ابر و میکروسرویسها (Cloud & Microservices)
.NET 8 شامل ابزارها و قابلیتهای جدیدی برای توسعه و اجرای میکروسرویسها در ابر (Cloud) است. این ویژگیها شامل بهبودهایی در Docker، Kubernetes، و gRPC است که امکان ایجاد سرویسهای مقیاسپذیر و توزیعشده را سادهتر میکند.
- Native AOT (Ahead-of-Time Compilation)
.NET 8 از Native AOT برای کامپایل برنامهها به کد باینری Native پشتیبانی میکند. این ویژگی باعث میشود که برنامهها سریعتر اجرا شوند و حافظه کمتری مصرف کنند. این قابلیت به خصوص برای اپلیکیشنهای cross-platform و سناریوهایی که نیاز به اجرای سریعتر دارند، مفید است.
- بهبودهای EF Core 8 (Entity Framework Core 8)
EF Core 8 با بهبودهایی در زمینه عملکرد، انعطافپذیری بیشتر در مدیریت دادهها، و امکانات پیشرفتهتر برای LINQ و SQL Queries، استفاده از پایگاه دادهها را در پروژههای بزرگ بهینهتر کرده است. همچنین پشتیبانی از Query های پیچیده و بهبود در مدلهای داده از دیگر نقاط قوت EF Core 8 است.
- پشتیبانی از gRPC بهبود یافته
در .NET 8، gRPC به طور قابل توجهی بهبود یافته و برای ارتباطات کارآمدتر و سریعتر بین میکروسرویسها طراحی شده است. gRPC در زمینههای ارتباطات بین سرویسها، مصرف کمتر منابع، و عملکرد بهتر نسبت به HTTP APIهای سنتی بهینهسازی شده است.
- پشتیبانی از MAUI (Multi-platform App UI)
.NET 8 از MAUI پشتیبانی بهتری ارائه میدهد، که امکان ایجاد اپلیکیشنهای چندسکویی برای ویندوز، macOS، iOS و Android با استفاده از یک کدبیس مشترک را فراهم میکند. این ویژگی برای توسعهدهندگانی که به دنبال ایجاد اپلیکیشنهای موبایل و دسکتاپ هستند بسیار مفید است.
- ارتقاء امنیت (Security Enhancements)
.NET 8 شامل بهبودهای امنیتی جدیدی است که به توسعهدهندگان اجازه میدهد اپلیکیشنهایی با امنیت بالاتر ایجاد کنند. این بهبودها شامل ابزارها و روشهای جدید برای محافظت در برابر حملات XSS، CSRF، و SQL Injection است.
- پشتیبانی بهتر از DevOps و CI/CD
.NET 8 با سیستمهای Continuous Integration/Continuous Deployment (CI/CD) یکپارچگی بهتری دارد. این شامل بهینهسازیهایی برای اجرای تستهای خودکار، تحلیل کد، و مدیریت استقرار در محیطهای مختلف است.
- پشتیبانی از Minimal APIs
.NET 8 امکانات بیشتری برای Minimal APIs ارائه میدهد. این نوع APIها با نوشتن کد کمتر و سادگی بیشتر، مناسب برای ایجاد سرویسهای کوچک و ساده یا میکروسرویسهای خاص میباشند. همچنین Minimal APIs با بهینهسازیهای جدید کارایی بهتری دارد.
- پشتیبانی بهتر از Hot Reload
Hot Reload در .NET 8 بهبود یافته است، که به توسعهدهندگان اجازه میدهد کدها را بدون نیاز به کامپایل مجدد و راهاندازی مجدد برنامه تغییر دهند. این ویژگی باعث افزایش بهرهوری توسعهدهندگان در زمان تغییرات کوچک در کد میشود.
- یکپارچگی با ابزارهای توسعهدهندگان (Developer Tools Integration)
.NET 8 با ابزارهایی مانند Visual Studio 2022 و Visual Studio Code بهبود یافته و امکان یکپارچگی بهتر و استفاده از ویژگیهای جدید مانند Code Analysis و Refactoring در این محیطها فراهم شده است.
- ارتقاء در مدیریت حافظه (Memory Management)
.NET 8 دارای بهبودهایی در زمینه مدیریت حافظه است که باعث مصرف بهینهتر منابع سیستم میشود. این ارتقاءها به خصوص در زمینه برنامههای با عملکرد بالا و سرورهای مقیاسپذیر تاثیرگذار است.
- Cross-Platform بهبود یافته
.NET 8 تجربه بهتری از توسعه Cross-Platform ارائه میدهد. این نسخه به توسعهدهندگان اجازه میدهد که به راحتی برنامههایی برای ویندوز، لینوکس و macOS ایجاد کنند و این کار با بهینهسازیهای بومی در پلتفرمهای مختلف همراه است.
نتیجهگیری
.NET 8 با بهبودهای عملکردی، پشتیبانی بهتر از ابزارها و تکنولوژیهای مدرن، امکانات امنیتی پیشرفته و قابلیتهای بیشتری برای توسعه APIها، اپلیکیشنهای چندسکویی، و میکروسرویسها یک انتخاب عالی برای توسعهدهندگان است. این نسخه با فراهم کردن ویژگیهای جدید و بهبودهای مختلف به توسعهدهندگان کمک میکند تا سریعتر، امنتر و با کیفیتتر پروژههای خود را پیادهسازی کنند.
آیا SqlCommand در asp.net core ، Sql Injection میخورد ؟
در ASP.NET Core، استفاده از شیء SqlCommand به صورت مستقیم میتواند به آسیبپذیری SQL Injection منجر شود، اگر ورودیهای کاربر بدون اعتبارسنجی یا پاکسازی مناسب مستقیماً در queryهای SQL قرار گیرند. SQL Injection یک نوع حمله است که در آن مهاجم میتواند دستورات SQL را به query شما تزریق کند و باعث دسترسی غیرمجاز یا تغییر دادهها در پایگاه داده شود.
مثال از SQL Injection
اگر از SqlCommand به شکل زیر استفاده کنید و ورودی کاربر مستقیماً در query گنجانده شود، برنامه شما ممکن است در برابر SQL Injection آسیبپذیر باشد:
string query = $”SELECT * FROM Users WHERE Username = ‘{username}’ AND Password = ‘{password}'”;
SqlCommand cmd = new SqlCommand(query, connection);
در این مثال، مهاجم میتواند مقادیر مخرب مانند ” OR 1=1 –” را به جای مقدار username وارد کند و باعث اجرای دستورات غیرمجاز شود.
جلوگیری از SQL Injection با استفاده از پارامترها (Parameterized Queries)
برای جلوگیری از SQL Injection، باید از Parameterized Queries استفاده کنید. در این روش، به جای قرار دادن مستقیم مقادیر در query، از پارامترها استفاده میشود. این کار باعث میشود که مقادیر ورودی به عنوان دادههای ساده در query در نظر گرفته شوند و امکان تزریق کدهای مخرب از بین برود.
مثال ایمن با استفاده از پارامترهای SQL:
string query = “SELECT * FROM Users WHERE Username = @username AND Password = @password”;
SqlCommand cmd = new SqlCommand(query, connection);
cmd.Parameters.AddWithValue(“@username”, username);
cmd.Parameters.AddWithValue(“@password”, password);
در این روش، مقادیر username و password به صورت امن به query اضافه میشوند و حتی اگر مهاجم سعی کند کد SQL تزریق کند، به دلیل استفاده از پارامترها، query به طور صحیح اجرا میشود و از اجرای دستورات ناخواسته جلوگیری میشود.
جمعبندی:
اگر از SqlCommand به همراه قرار دادن مستقیم مقادیر ورودی کاربر در query استفاده کنید، برنامه شما ممکن است در برابر SQL Injection آسیبپذیر باشد.
برای جلوگیری از SQL Injection، همواره از Parameterized Queries استفاده کنید.
ابزارهای ORM مانند Entity Framework نیز به صورت پیشفرض از پارامترها برای جلوگیری از SQL Injection استفاده میکنند، بنابراین اگر از این ابزارها استفاده میکنید، به طور خودکار محافظت بیشتری در برابر این حملات خواهید داشت.
معایب استفاده از Include() و ThenInclude() در ef در ASP.Net core و راه حل آن ؟
در Entity Framework (EF) ، متدهای Include() و ThenInclude() برای بارگذاری رابطهها و دادههای مرتبط (Eager Loading) استفاده میشوند. در حالی که این متدها به راحتی امکان بارگذاری دادههای مرتبط را فراهم میکنند، اما معایبی نیز دارند که میتوانند منجر به مشکلات عملکردی شوند. در ادامه به بررسی این معایب و راهحلهای جایگزین پرداخته میشود:
معایب استفاده از Include() و ThenInclude()
افزایش تعداد جوینها (Joins) در کوئریها
استفاده از Include() و ThenInclude() میتواند باعث ایجاد join های زیادی در کوئری شود. این امر مخصوصاً در صورتی که رابطههای زیادی بین جداول وجود داشته باشد یا دادههای مرتبط پیچیده باشند، باعث تولید کوئریهای بزرگ و پیچیده میشود.
این کوئریهای بزرگ میتوانند باعث افزایش زمان اجرای کوئری و کاهش کارایی دیتابیس شوند.
Over-fetching یا بارگذاری دادههای غیرضروری
Include() تمام دادههای مربوط به رابطههای مشخص شده را بارگذاری میکند، حتی اگر تنها به بخشی از این دادهها نیاز داشته باشید. این به معنای بارگذاری دادههای غیرضروری و افزایش حجم دادههای دریافتی از دیتابیس است که میتواند سرعت و کارایی برنامه را کاهش دهد.
مشکل با عملکرد در دادههای بزرگ
وقتی که تعداد رکوردها یا اندازه دادههای مربوطه بزرگ باشد، استفاده از Include() و ThenInclude() میتواند منجر به استفاده زیاد از حافظه و افزایش زمان پاسخدهی سیستم شود. دلیل این امر این است که تمامی دادههای مرتبط در یک کوئری بازیابی میشوند و ممکن است منابع سیستم به شدت تحت فشار قرار بگیرند.
پیچیدگی در کوئریهای چند سطحی
در سناریوهایی که روابط چند سطحی وجود دارد (مانند One-to-Many-to-Many)، استفاده از ThenInclude() میتواند کد را پیچیده و دشوار برای خواندن کند. همچنین این نوع کوئریها میتوانند به کوئریهای بسیار پیچیده SQL تبدیل شوند که مدیریت و بهینهسازی آنها سخت است.
راهحلها و جایگزینها
Lazy Loading
در Lazy Loading ، دادههای مرتبط به صورت خودکار در زمان دسترسی به آنها بارگذاری میشوند. اگر نیاز به بارگذاری همه دادههای مرتبط در یک زمان مشخص ندارید، میتوانید از Lazy Loading استفاده کنید تا تنها در زمان مورد نیاز دادهها بارگذاری شوند.
با این حال، باید توجه داشت که Lazy Loading نیز میتواند منجر به ایجاد چندین درخواست به دیتابیس شود که به عنوان N+1 Problem شناخته میشود. بنابراین باید با احتیاط استفاده شود.
public class MyDbContext : DbContext
{
public MyDbContext()
{
this.ChangeTracker.LazyLoadingEnabled = true;
}
}Explicit Loading (بارگذاری صریح)
به جای استفاده از Include() و ThenInclude() برای بارگذاری تمامی دادههای مرتبط، میتوانید از Explicit Loading استفاده کنید. در این روش، شما به صورت صریح و تنها زمانی که به دادههای مرتبط نیاز دارید، آنها را بارگذاری میکنید. این روش کنترل بیشتری بر روی بارگذاری دادهها فراهم میکند.
var order = context.Orders.Find(orderId);
context.Entry(order).Collection(o => o.OrderItems).Load();استفاده از Projection با Select
یکی از بهترین روشها برای اجتناب از مشکلات Include() و ThenInclude() استفاده از Projection است. با استفاده از متد Select() ، میتوانید فقط دادههایی که نیاز دارید را از دیتابیس انتخاب کنید. این کار به کاهش بار روی دیتابیس و بهینهسازی کوئریها کمک میکند.
var result = context.Orders
.Where(o => o.OrderId == orderId)
.Select(o => new {
o.OrderId,
o.Customer.Name,
OrderItems = o.OrderItems.Select(oi => new {
oi.ProductName,
oi.Quantity
})
}).ToList();با این روش، تنها فیلدهای مورد نیاز از دیتابیس انتخاب میشوند و از بارگذاری دادههای غیرضروری جلوگیری میشود.
افزایش بهینهسازی کوئریها با استفاده از Stored Procedures
در برخی موارد، استفاده از Stored Procedures در دیتابیس میتواند به بهبود عملکرد کمک کند. اگر کوئریهای پیچیده دارید که نیاز به جوینهای متعدد دارند، میتوانید به جای استفاده از Include()، این عملیات را در Stored Procedure انجام داده و نتایج را بازیابی کنید.
Cache کردن دادههای مرتبط
اگر دادههای مرتبط به صورت ثابت تغییر نمیکنند، میتوانید از Caching استفاده کنید. این امر باعث کاهش تعداد درخواستهای به دیتابیس میشود و از بارگذاری مکرر دادههای مشابه جلوگیری میکند.
استفاده از Data Transfer Objects (DTO)
برای بارگذاری دادههای مورد نیاز و جلوگیری از over-fetching، استفاده از DTO یا ViewModelها میتواند بسیار مؤثر باشد. در این روش، تنها دادههای ضروری برای ارسال به کلاینت انتخاب و بهینه میشوند.
نتیجهگیری:
در حالی که Include() و ThenInclude() ابزاری مناسب برای بارگذاری دادههای مرتبط در EF هستند، اما استفاده بیش از حد یا نادرست از آنها میتواند مشکلات عملکردی جدی ایجاد کند. راهحلهای جایگزینی مانند Lazy Loading، Explicit Loading، Projection با Select()، و استفاده از Stored Procedures میتوانند به بهبود کارایی و جلوگیری از بارگذاری دادههای غیرضروری کمک کنند.
مزایای استفاده از SSO در پروژه های ASP.Net Core
استفاده از SSO (Single Sign-On) در پروژههای ASP.NET Core مزایای متعددی دارد که به بهبود امنیت، تجربه کاربری و مدیریت سادهتر هویتها کمک میکند. در ادامه به برخی از مهمترین مزایای استفاده از SSO در پروژههای .NET Core اشاره میشود:
- تجربه کاربری بهبود یافته (Improved User Experience)
با استفاده از SSO، کاربران تنها یک بار وارد سیستم میشوند و سپس میتوانند به تمام برنامهها و سرویسهای مرتبط بدون نیاز به وارد کردن دوباره اطلاعات ورود دسترسی پیدا کنند. این موضوع تجربه کاربری را به شدت بهبود میبخشد و نیاز به ورود مکرر به هر سیستم را حذف میکند.
- مدیریت سادهتر هویتها (Simplified Identity Management)
با SSO، مدیریت هویت کاربران تنها در یک مکان متمرکز میشود. این بدان معناست که اگر نیاز به تغییر اطلاعات کاربری، تنظیم دسترسیها، یا مسدود کردن حساب کاربری باشد، این تغییرات تنها در یک سیستم انجام میشود و به صورت خودکار در همه سرویسها و اپلیکیشنهای مرتبط اعمال میشود.
- افزایش امنیت (Enhanced Security)
SSO امنیت را افزایش میدهد زیرا کاربران تنها یک بار به سیستم وارد میشوند و نیاز به مدیریت و به خاطر سپردن چندین نام کاربری و رمز عبور را ندارند. این کاهش استفاده از رمز عبورهای متعدد احتمال استفاده از رمزهای ضعیف یا تکراری را کاهش میدهد. همچنین استفاده از Multi-Factor Authentication (MFA) به سادگی در SSO پیادهسازی میشود.
به علاوه، مکانیزمهای پیشرفته احراز هویت مانند OAuth 2.0، OpenID Connect و SAML که معمولاً در SSO استفاده میشوند، از استانداردهای امنیتی بالایی برای تبادل اطلاعات بین سیستمها برخوردارند.
- کاهش بار مدیریت برای تیمهای IT
از آنجایی که با استفاده از SSO، کاربران فقط یک حساب کاربری دارند، تیمهای IT کمتر با درخواستهای فراموشی رمز عبور یا مشکلات ورود مکرر کاربران مواجه میشوند. این امر به کاهش حجم کار تیمهای پشتیبانی کمک کرده و مدیریت سادهتری از حسابهای کاربری به وجود میآورد.
- یکپارچگی با سرویسهای مختلف
SSO به راحتی با سرویسهای مختلف و پلتفرمهای گوناگون یکپارچه میشود. بسیاری از سیستمهای Identity Provider مانند Azure AD، Okta، Auth0 از پروتکلهای SSO پشتیبانی میکنند و امکان یکپارچهسازی آسان بین اپلیکیشنهای مختلف (اعم از اپلیکیشنهای داخلی و سرویسهای ابری) را فراهم میآورند.
در ASP.NET Core، استفاده از کتابخانههایی مانند OpenIddict و IdentityServer4 نیز به راحتی امکان پیادهسازی SSO با پروتکلهای رایج را فراهم میکند.
- کاهش خطرات امنیتی
با استفاده از SSO، تعداد دفعاتی که کاربران نیاز به وارد کردن اطلاعات ورود دارند کاهش مییابد، که این امر خطرات امنیتی مرتبط با حملات Phishing و Man-in-the-Middle را نیز کاهش میدهد.
علاوه بر این، SSO امکان پیادهسازی و اعمال سیاستهای امنیتی متمرکز مانند Session Timeout و Single Logout را نیز فراهم میکند، که در نهایت به بهبود امنیت کلی سیستم منجر میشود.
- قابلیت مقیاسپذیری (Scalability)
با SSO، افزودن اپلیکیشنها یا سرویسهای جدید به یک سازمان به سادگی انجام میشود، زیرا مدیریت هویت به صورت متمرکز و در یک سرویس هویتی انجام میشود. این ویژگی برای سازمانهایی که به سرعت رشد میکنند یا از اپلیکیشنهای متعددی استفاده میکنند، بسیار مهم است.
- یکپارچگی آسان با احراز هویت چندعاملی (MFA)
SSO به راحتی با Multi-Factor Authentication (MFA) یکپارچه میشود و کاربران میتوانند از یک مرحله ورود امنتر استفاده کنند. به این ترتیب، حتی اگر حساب کاربری یکی از کاربران به خطر بیافتد، مراحل دیگر احراز هویت مانع دسترسی غیرمجاز میشود.
- تمرکز روی توسعهی اپلیکیشنها
استفاده از SSO و سیستمهای مدیریت هویت یکپارچه باعث میشود توسعهدهندگان بیشتر روی توسعه قابلیتهای اصلی اپلیکیشنها تمرکز کنند، به جای اینکه زمان زیادی را برای مدیریت سیستم احراز هویت در هر اپلیکیشن صرف کنند.
- Single Logout
در SSO، ویژگی Single Logout یا خروج یکپارچه وجود دارد. با این ویژگی، وقتی کاربر از یک سرویس خارج میشود، به صورت خودکار از سایر سرویسها و اپلیکیشنهای مرتبط نیز خارج میشود. این ویژگی به خصوص در سازمانهایی با دسترسی به چندین اپلیکیشن بسیار مفید است و امنیت را بهبود میبخشد.
- مهاجرت آسان بین پلتفرمها
با استفاده از SSO، تغییر پلتفرمهای مورد استفاده برای احراز هویت یا مهاجرت از یک سیستم به سیستم دیگر بدون نیاز به تغییرات اساسی در اپلیکیشنها و سرویسها انجام میشود. به این معنا که اگر سازمان تصمیم بگیرد از یک سیستم هویت دیگر استفاده کند، با تنظیمات مربوط به SSO، این تغییر به سادگی امکانپذیر است.
- پیادهسازی استانداردهای شناختهشده امنیتی
SSO معمولاً از پروتکلهای شناخته شدهای مانند OAuth 2.0 و OpenID Connect استفاده میکند که استانداردهای بینالمللی برای احراز هویت و مدیریت دسترسی هستند. این پروتکلها تضمین میکنند که امنیت و انعطافپذیری در فرآیند احراز هویت به صورت مطلوب رعایت شود.
نتیجهگیری
استفاده از SSO در پروژههای ASP.NET Core باعث بهبود امنیت، افزایش راحتی کاربران، کاهش حجم کارهای مدیریتی، و بهبود یکپارچگی میان سرویسها و اپلیکیشنهای مختلف میشود. این رویکرد نه تنها به توسعهدهندگان کمک میکند تا تمرکز بیشتری بر روی قابلیتهای اصلی اپلیکیشن داشته باشند، بلکه باعث بهبود کارایی و بهرهوری کاربران و تیمهای IT نیز خواهد شد.
مزایای استفاده از openiddict در ASP.Net Core؟
OpenIddict یکی از محبوبترین کتابخانهها برای پیادهسازی SSO (Single Sign-On) و OAuth 2.0/ OpenID Connect در پروژههای ASP.NET Core است. استفاده از OpenIddict در پروژههای ASP.NET Core مزایای بسیاری دارد که در ادامه به بررسی آنها پرداخته میشود:
- پیادهسازی ساده و انعطافپذیر
OpenIddict یک کتابخانه انعطافپذیر است که امکان پیادهسازی پروتکلهای امنیتی مانند OAuth 2.0 و OpenID Connect را به شکلی ساده و کاربرپسند فراهم میکند. توسعهدهندگان بدون نیاز به پیچیدگیهای زیاد میتوانند قابلیتهایی مانند صدور Token، احراز هویت کاربران و مدیریت مجوزها را پیادهسازی کنند.
- پشتیبانی کامل از OAuth 2.0 و OpenID Connect
OpenIddict کاملاً از پروتکلهای OAuth 2.0 و OpenID Connect پشتیبانی میکند. این پروتکلها برای مدیریت مجوزها، احراز هویت و ارائه دسترسی به سرویسهای خارجی یا داخلی در برنامههای مدرن بسیار مهم هستند. استفاده از OpenIddict به شما اجازه میدهد که با استانداردهای امنیتی روز دنیا هماهنگ شوید.
- پشتیبانی از انواع Grant Types
OpenIddict از انواع Grant Types مانند Authorization Code, Implicit, Password, Client Credentials و Refresh Tokens پشتیبانی میکند. این قابلیت به شما اجازه میدهد تا مدل احراز هویت مناسب برای هر سناریویی را انتخاب کنید و آن را پیادهسازی کنید.
به عنوان مثال، در اپلیکیشنهای موبایل یا SPA (Single Page Applications) میتوان از Authorization Code Grant استفاده کرد، در حالی که برای سیستمهای بکاند از Client Credentials Grant بهرهبرداری میشود.
- پشتیبانی از پیادهسازی Authorization Server
OpenIddict میتواند به عنوان یک Authorization Server عمل کند و امکان صدور توکنهای دسترسی (Access Tokens) و توکنهای تأیید هویت (ID Tokens) را فراهم کند. این موضوع به شما اجازه میدهد تا به راحتی یک سرور هویت مرکزی برای مدیریت احراز هویت کاربران و مدیریت مجوزها ایجاد کنید.
- یکپارچگی با ASP.NET Core Identity
OpenIddict به خوبی با ASP.NET Core Identity یکپارچه میشود. این بدین معناست که شما میتوانید از سیستم مدیریت کاربران و نقشهای موجود در Identity برای مدیریت کاربران در OpenIddict استفاده کنید. این یکپارچگی باعث کاهش پیچیدگی و سهولت در پیادهسازی سیستمهای احراز هویت مبتنی بر نقش و دسترسی میشود.
- پشتیبانی از ذخیرهسازی دادههای توکن
OpenIddict امکان ذخیرهسازی دادههای مرتبط با توکنها (مانند Refresh Tokens و Authorization Codes) در دیتابیس را فراهم میکند. این قابلیت به شما امکان میدهد تا توکنها و سایر اطلاعات مرتبط را به صورت امن در یک دیتابیس ذخیره کنید و به راحتی مدیریت دوره زمانی اعتبار توکنها را انجام دهید.
- امنیت بالا
OpenIddict بر اساس پروتکلهای استاندارد OAuth 2.0 و OpenID Connect طراحی شده است که به صورت گسترده تست شده و از امنیت بالایی برخوردارند. همچنین میتوانید از ویژگیهای امنیتی مانند Token Revocation، Refresh Tokens، و Multi-Factor Authentication (MFA) به راحتی بهرهمند شوید.
- پشتیبانی از توکنهای JWT و سایر فرمتها
OpenIddict از توکنهای JWT (JSON Web Tokens) پشتیبانی میکند، که یکی از پرکاربردترین استانداردها برای انتقال اطلاعات هویتی به صورت امن بین سرورها و کلاینتها است. علاوه بر این، امکان پشتیبانی از سایر فرمتهای توکن (مانند Reference Tokens) نیز وجود دارد.
توکنهای JWT قابل اعتبارسنجی در هر نقطهای هستند و میتوانند اطلاعاتی مانند هویت کاربر و نقشهای او را به شکل امن در خود جای دهند.
- یکپارچگی با سایر سرویسهای OAuth 2.0 و OpenID Connect
با استفاده از OpenIddict، شما میتوانید به راحتی با سایر ارائهدهندگان هویت مانند Azure AD, Google, Facebook, و Okta یکپارچه شوید. این کار به کاربران اجازه میدهد تا با استفاده از حساب کاربری خود در این سرویسها وارد سیستم شما شوند.
- قابلیت سفارشیسازی بالا
OpenIddict قابلیت سفارشیسازی بالایی دارد و شما میتوانید بخشهای مختلف سیستم احراز هویت را به نیازهای پروژه خود تنظیم کنید. به عنوان مثال، میتوانید روشهای خاصی برای اعتبارسنجی کاربران، مدیریت توکنها، یا تولید کلیدهای امنیتی پیادهسازی کنید.
- مدیریت Scopes و Claims
با استفاده از OpenIddict، میتوانید Scopes و Claims را به صورت دقیق مدیریت کنید. Scopes به شما امکان میدهند که سطوح مختلف دسترسی را برای کاربران مشخص کنید، و Claims میتوانند اطلاعات مختلفی از کاربر مانند نام، ایمیل، یا نقشها را در توکنها جا بدهند. این ویژگی برای کنترل دسترسی دقیق و انعطافپذیر بسیار مفید است.
- مناسب برای معماریهای میکروسرویس
OpenIddict به خوبی در معماریهای Microservices قابل استفاده است. با استفاده از یک سرور مرکزی احراز هویت، میتوانید تمام سرویسها و میکروسرویسهای خود را به صورت متمرکز مدیریت کرده و کاربران را با توکنهای معتبر به سرویسها دسترسی دهید.
- پشتیبانی از Authorization Code Flow
OpenIddict از Authorization Code Flow، که امنترین روش برای مدیریت احراز هویت در اپلیکیشنهای تحت وب و موبایل است، پشتیبانی میکند. این روش به شما امکان میدهد تا به صورت امن توکنهای دسترسی را دریافت و مدیریت کنید.
- منبع باز و پشتیبانی از جامعه
OpenIddict یک پروژه منبع باز است که توسط جامعه توسعهدهندگان پشتیبانی میشود. به دلیل اینکه این پروژه بر روی GitHub قرار دارد، میتوانید به راحتی به کد منبع دسترسی داشته باشید، آن را برای نیازهای خود سفارشی کنید یا از انجمن کاربران برای حل مشکلات و پشتیبانی استفاده کنید.
- مستندسازی و راهنماهای کامل
OpenIddict مستندات جامعی دارد که به توسعهدهندگان کمک میکند تا به راحتی با نحوه استفاده از این کتابخانه آشنا شوند و آن را در پروژههای خود پیادهسازی کنند. همچنین نمونههای کد و راهنماهای متعددی برای سناریوهای مختلف ارائه شده است.
نتیجهگیری
OpenIddict یک انتخاب عالی برای پیادهسازی OAuth 2.0 و OpenID Connect در پروژههای ASP.NET Core است. این کتابخانه امکانات متعددی برای مدیریت امنیت، احراز هویت و دسترسی کاربران ارائه میدهد و میتواند به راحتی با سیستمهای هویت دیگر یکپارچه شود. OpenIddict با پشتیبانی از توکنهای JWT، مدیریت Scopes و Claims، و قابلیت سفارشیسازی بالا، به شما امکان میدهد تا یک سیستم امن و کارآمد برای مدیریت دسترسیها و هویت کاربران ایجاد کنید.
مزایای استفاده از RabbitMQ در پروژه های ASP.Net Core
استفاده از RabbitMQ در پروژههای .NET Core مزایای متعددی در مدیریت پیامها و ارتباطات میان سرویسها بهویژه در سیستمهای میکروسرویسی دارد. در ادامه به بررسی مهمترین مزایای استفاده از RabbitMQ در این نوع پروژهها پرداخته میشود:
- ارتباط غیرهمزمان (Asynchronous Communication)
RabbitMQ امکان برقراری ارتباطات غیرهمزمان میان سرویسها را فراهم میکند. این ویژگی به سیستم اجازه میدهد تا در مواقعی که نیاز به پاسخ فوری از یک سرویس نیست، پیامها را در صف قرار داده و پردازش آنها را به زمانی که منابع کافی در دسترس است، موکول کند. این کار میتواند بهرهوری سیستم را افزایش دهد و مانع از بروز مشکلات عملکردی شود.
- مقیاسپذیری (Scalability)
RabbitMQ به راحتی میتواند به مقیاسهای بزرگ افزایش یابد و با اضافه کردن مصرفکنندهها (Consumers) یا صفهای پیام (Queues) جدید، سیستم را مقیاسپذیر کند. در سیستمهای میکروسرویس، این قابلیت بسیار ارزشمند است، زیرا به شما امکان میدهد پیامها را به صورت بارگذاری متعادل بین چندین سرویس توزیع کنید.
- پشتیبانی از الگوهای مختلف پیامرسانی (Messaging Patterns)
RabbitMQ از الگوهای مختلف پیامرسانی مانند Publish/Subscribe, Request/Response, Work Queues، و Routing پشتیبانی میکند. این الگوها به شما امکان میدهند سیستمهای پیچیدهای را برای ارسال و دریافت پیامها بین سرویسها پیادهسازی کنید، بهخصوص در شرایطی که سرویسها باید به صورت همزمان یا ترتیبی با هم تعامل داشته باشند.
- تحمل خطا (Fault Tolerance)
RabbitMQ امکان پیادهسازی مکانیسمهایی برای تحمل خطا را فراهم میکند. به عنوان مثال، اگر یک سرویس در زمان پردازش پیامها از کار بیافتد، پیامها همچنان در صف باقی میمانند تا زمانی که سرویس دوباره فعال شود. این ویژگی مانع از دست رفتن دادهها و از بین رفتن پیامها در مواقع بحرانی میشود.
- مدیریت بار کاری (Workload Balancing)
RabbitMQ به شما امکان میدهد بار کاری بین چندین مصرفکننده توزیع شود. به این ترتیب، بارکاری سنگین به صورت متوازن بین سرویسها تقسیم میشود. این ویژگی در سیستمهایی با بار ترافیک بالا یا تعداد زیادی از پردازشهای همزمان بسیار مفید است.
- تضمین تحویل پیام (Message Delivery Guarantee)
RabbitMQ با پشتیبانی از تضمین تحویل پیام، پیامها را تا زمانی که مصرفکنندهها آنها را به درستی دریافت و پردازش نکنند، ذخیره میکند. این تضمین شامل مکانیزمهای Ack (Acknowledgement) است که مصرفکنندهها پس از پردازش پیام به RabbitMQ ارسال میکنند تا پیام از صف حذف شود. اگر یک مصرفکننده پیام را پردازش نکند، پیام دوباره به صف بازگردانده میشود.
- جدا کردن سرویسها (Service Decoupling)
RabbitMQ باعث کاهش وابستگی مستقیم بین سرویسها میشود. به جای ارتباط مستقیم بین سرویسها، از صفهای پیام برای ارسال و دریافت پیامها استفاده میشود که این امر باعث افزایش انعطافپذیری، کاهش پیچیدگی و بهبود پایداری سیستم میشود.
- پشتیبانی از چندین زبان برنامهنویسی
RabbitMQ از چندین زبان برنامهنویسی مختلف مانند C#, Java, Python, Ruby و بسیاری دیگر پشتیبانی میکند. این ویژگی به شما امکان میدهد تا به راحتی از RabbitMQ در محیطهای مختلف با زبانهای متفاوت استفاده کنید، به خصوص در سیستمهای میکروسرویسی که هر سرویس ممکن است با یک زبان مختلف پیادهسازی شده باشد.
- قابلیت نظارت و مانیتورینگ (Monitoring)
RabbitMQ دارای داشبوردهای نظارتی قدرتمندی است که وضعیت صفها، پیامها، و مصرفکنندهها را به صورت لحظهای نمایش میدهد. با استفاده از این داشبوردها، شما میتوانید بر عملکرد سیستم نظارت کنید و در صورت بروز مشکل، به سرعت آن را شناسایی و رفع کنید.
- امنیت بالا
RabbitMQ با ارائه ویژگیهای امنیتی مانند TLS (Transport Layer Security) برای رمزنگاری ارتباطات و Authentication/Authorization برای کنترل دسترسی، امنیت پیامها و ارتباطات را تضمین میکند. این ویژگیها برای سیستمهایی که دادههای حساس منتقل میکنند، بسیار حائز اهمیت است.
- پشتیبانی از پیامهای پایدار (Persistent Messaging)
پیامها در RabbitMQ میتوانند به صورت پایدار ذخیره شوند، به این معنا که حتی در صورت بروز خطا یا خاموشی سرورها، پیامها از دست نمیروند و در زمان روشن شدن مجدد سرور، همچنان در دسترس هستند.
- توزیع بار به صورت موازی (Parallel Processing)
RabbitMQ از موازیسازی پردازش پیامها پشتیبانی میکند. این بدان معناست که چندین مصرفکننده میتوانند به طور همزمان پیامها را از یک یا چند صف مصرف کنند، که این ویژگی کارایی سیستم را به میزان قابل توجهی افزایش میدهد.
- پشتیبانی از Cluster و High Availability
RabbitMQ از کلاسترینگ پشتیبانی میکند که امکان توزیع پیامها بین چندین سرور را فراهم میکند. همچنین قابلیت High Availability (در دسترسپذیری بالا) را دارد که مانع از بروز قطعی در دسترسی به پیامها در صورت از کار افتادن یکی از گرههای کلاستر میشود.
- سازگاری با معماریهای Event-Driven
RabbitMQ به خوبی با معماریهای مبتنی بر رویداد (Event-Driven) سازگار است. در این نوع معماریها، سیستمها به جای ارتباطات مستقیم، از پیامها و رویدادها برای تبادل داده استفاده میکنند که باعث افزایش استقلال و کاهش وابستگی سرویسها میشود.
- کاهش تاخیر و بهبود کارایی
استفاده از RabbitMQ به بهبود کارایی سیستم و کاهش تاخیر در ارتباطات میان سرویسها کمک میکند. به دلیل ساختار صفبندی پیامها، سیستم میتواند بار ترافیکی را مدیریت کرده و پیامها را در زمانی که منابع در دسترس است، پردازش کند.
نتیجهگیری
RabbitMQ در پروژههای .NET Core به عنوان یک سیستم مدیریت پیام قوی و قابل اعتماد شناخته میشود. این فناوری با ارائه ارتباطات غیرهمزمان، مقیاسپذیری بالا، تضمین تحویل پیام، و پشتیبانی از الگوهای مختلف پیامرسانی، میتواند به بهبود عملکرد و پایداری سیستمهای بزرگ و پیچیده کمک کند. به خصوص در پروژههای میکروسرویسی که سرویسها نیاز به تبادل پیامهای زیاد و پردازش همزمان دارند، RabbitMQ میتواند یک راهحل ایدهآل باشد.
مزایای استفاده از Exception Handler در پروژه های ASP.Net Core
استفاده از Exception Handler (مدیریت استثنا) در پروژههای .NET Core مزایای متعددی دارد که به بهبود کیفیت کد، مدیریت خطاها و تجربه کاربری کمک میکند. در ادامه به بررسی مهمترین مزایای استفاده از Exception Handler در این نوع پروژهها میپردازیم:
- مرکزیت در مدیریت خطاها
با استفاده از Exception Handler، میتوانید تمام استثناهای مربوط به اپلیکیشن را در یک مکان متمرکز مدیریت کنید. این کار باعث کاهش تکرار کد و سهولت در نگهداری و بهروزرسانی آن میشود. به عنوان مثال، میتوانید یک middleware برای مدیریت استثناها تعریف کرده و آن را در pipeline درخواستها قرار دهید.
- کاهش پیچیدگی
با مدیریت خطاها در یک نقطه مرکزی، کد شما سادهتر و خواناتر خواهد شد. شما میتوانید کدهای مربوط به مدیریت خطاها را از منطق کسبوکار جدا کنید و این باعث میشود که کد شما قابل فهمتر باشد.
- گزارشگیری و لاگگذاری (Logging)
Exception Handler به شما این امکان را میدهد که هنگام بروز خطا، اطلاعات مفیدی درباره آن جمعآوری کنید. با لاگگذاری استثناها، میتوانید از دلایل خطاها و زمانهای بروز آنها آگاه شوید و این اطلاعات به شما در عیبیابی و رفع مشکلات کمک میکند.
- مدیریت پاسخهای خطا
با استفاده از Exception Handler، میتوانید پاسخهای مناسبی به کلاینتها ارسال کنید. به جای اینکه خطاها به صورت ناخواسته به کاربر نشان داده شوند، میتوانید یک پیام خطای کاربرپسند و مناسب را ارسال کنید که شامل جزئیات فنی نباشد. این کار به بهبود تجربه کاربری کمک میکند.
- امنیت بالا
با استفاده از Exception Handler، میتوانید جزئیات حساس خطاها را از کاربر پنهان کنید. به جای اینکه پیامهای خطای داخلی (که ممکن است اطلاعات حساس را فاش کند) به کاربر نشان دهید، میتوانید پیامهای عمومی و ایمن ارسال کنید که باعث افزایش امنیت اپلیکیشن میشود.
- امکان استفاده از الگوهای طراحی
با استفاده از Exception Handler میتوانید از الگوهای طراحی مانند Chain of Responsibility یا Strategy Pattern برای مدیریت خطاها استفاده کنید. این کار به شما کمک میکند تا خطاها را به صورت مؤثرتری مدیریت کنید و پیادهسازیهای مختلفی برای هر نوع خطا داشته باشید.
- گزارش خطا به صورت خودکار
میتوانید Exception Handler را به گونهای پیکربندی کنید که هنگام بروز خطا، اطلاعات آن به صورت خودکار به یک سیستم گزارشگیری یا پایگاه داده ارسال شود. این کار باعث میشود که بتوانید به سرعت از بروز مشکلات آگاه شوید و اقدامات لازم را انجام دهید.
- مدیریت استثناهای خاص
شما میتوانید انواع مختلف استثناها (مانند استثناهای مربوط به پایگاه داده، اعتبارسنجی و غیره) را مدیریت کرده و برای هر کدام رفتار خاصی تعریف کنید. به این ترتیب، میتوانید پاسخهای متناسب با نوع خطا را به کلاینتها ارسال کنید.
- تست آسانتر
با مدیریت متمرکز خطاها، تست واحد (Unit Testing) و تست یکپارچه (Integration Testing) آسانتر میشود. شما میتوانید استثناها را به سادگی شبیهسازی کرده و بررسی کنید که اپلیکیشن چگونه به خطاها واکنش نشان میدهد.
- قابلیت سفارشیسازی
میتوانید Exception Handler را به دلخواه خود سفارشیسازی کنید. به عنوان مثال، میتوانید تصمیم بگیرید که چه نوع خطاهایی را ثبت کنید یا چگونه به آنها پاسخ دهید. این قابلیت به شما امکان میدهد که رفتار اپلیکیشن را بر اساس نیازهای خاص خود تنظیم کنید.
- تحلیل عملکرد
میتوانید با ثبت اطلاعات مربوط به استثناها، تحلیلهای عملکردی انجام دهید. این اطلاعات به شما کمک میکند تا بخشهای ناکارآمد یا مشکلدار سیستم را شناسایی کنید و بهبودهای لازم را انجام دهید.
- بهبود استقامت اپلیکیشن
با مدیریت مؤثر استثناها، میتوانید اطمینان حاصل کنید که اپلیکیشن شما در برابر خطاها مقاومتر است. به عنوان مثال، میتوانید تلاشهای مجدد (Retry Mechanism) را برای پردازش خطاهای موقتی پیادهسازی کنید تا اپلیکیشن به طور مداوم در حال کار باشد.
نتیجهگیری
استفاده از Exception Handler در پروژههای .NET Core به بهبود مدیریت خطاها، افزایش امنیت، کاهش پیچیدگی کد و بهبود تجربه کاربری کمک میکند. این امر به شما اجازه میدهد تا یک سیستم پایدار و قابل اعتماد بسازید که بتواند به درستی به خطاها واکنش نشان دهد و اطلاعات مفیدی را برای عیبیابی و بهبود عملکرد فراهم کند.
مزایای استفاده از Blazor با Angular در پروژه های ASP.Net Core
استفاده از Blazor و Angular در پروژههای .NET Core میتواند مزایای متعددی به همراه داشته باشد. هر دو فناوری دارای ویژگیها و قابلیتهای خاص خود هستند که میتوانند به بهبود عملکرد، تجربه کاربری و کارایی کلی اپلیکیشن کمک کنند. در ادامه به بررسی مهمترین مزایای استفاده همزمان از Blazor و Angular در این نوع پروژهها میپردازیم:
- تفکیک کارکردها
Blazor میتواند برای مدیریت منطق و APIهای سمت سرور استفاده شود، در حالی که Angular میتواند به عنوان یک فریمورک قدرتمند برای توسعه UI (رابط کاربری) عمل کند. این تفکیک میتواند به مدیریت بهتر و سازماندهی کد کمک کند.
- بهرهوری از توانمندیهای Blazor
Blazor به توسعهدهندگان این امکان را میدهد که با استفاده از زبان C# و .NET، اپلیکیشنهای وب تعاملی بسازند. این امر به توسعهدهندگان .NET این امکان را میدهد که از مهارتهای موجود خود بهره ببرند و از قابلیتهای پیشرفته C# و .NET در سمت سرور استفاده کنند.
- استفاده از اجزای مشترک
با استفاده از Blazor و Angular میتوان اجزای مشترکی را ایجاد کرد که در هر دو فریمورک استفاده شود. به عنوان مثال، میتوان از کتابخانههای مشترک برای مدیریت دادهها و منطق تجاری استفاده کرد که این امر باعث کاهش تکرار و بهبود کارایی میشود.
- تجربه کاربری غنی
Angular به عنوان یک فریمورک SPA (Single Page Application) شناخته میشود و میتواند تجربه کاربری بسیار روان و تعاملی را فراهم کند. ترکیب آن با Blazor میتواند به ایجاد تجربه کاربری غنیتری منجر شود که به راحتی بتواند با APIهای موجود در سمت سرور تعامل کند.
- مدیریت وضعیت (State Management)
با استفاده از Blazor برای مدیریت وضعیت اپلیکیشن و Angular برای UI، میتوان مدیریت وضعیت مؤثری را در اپلیکیشن پیادهسازی کرد. این کار به حفظ و انتقال وضعیتهای مختلف در بین اجزای UI کمک میکند.
- توسعه سریعتر
با استفاده از Blazor در کنار Angular، توسعهدهندگان میتوانند از ابزارها و الگوهای توسعهای که هر دو فریمورک ارائه میدهند بهره ببرند. این باعث میشود که روند توسعه سریعتر و مؤثرتر باشد.
- قابلیت تست آسانتر
استفاده از هر دو فریمورک به شما این امکان را میدهد که تستهای واحد و یکپارچه را به سادگی انجام دهید. میتوانید منطق تجاری را با Blazor و UI را با Angular تست کنید و این کار باعث افزایش کیفیت کد میشود.
- دسترسپذیری بالا
Blazor با قابلیتهای سمت سرور خود میتواند دسترسی به دادهها و منطق تجاری را به آسانی فراهم کند. این قابلیت به شما امکان میدهد که با استفاده از APIهای Angular، دادهها را به راحتی بارگذاری و مدیریت کنید.
- استفاده از فناوریهای روز
با استفاده از Blazor و Angular، میتوانید از جدیدترین فناوریها و الگوهای توسعه وب بهرهمند شوید. این دو فریمورک به طور مداوم بهروزرسانی میشوند و از آخرین ویژگیها و قابلیتها پشتیبانی میکنند.
- پشتیبانی از فریمورکهای مختلف
Blazor و Angular هر دو از فریمورکهای مختلفی پشتیبانی میکنند. این امر به شما این امکان را میدهد که به راحتی با سایر فریمورکها و کتابخانهها در اکوسیستم .NET و جاوا اسکریپت ترکیب شوید.
- امنیت بالا
Blazor به دلیل قابلیتهای سمت سرور خود، میتواند از امنیت بالایی برخوردار باشد. با استفاده از Blazor در کنار Angular، میتوانید اطمینان حاصل کنید که دادهها و ارتباطات به صورت امن مدیریت میشوند.
- امکان استفاده از کتابخانههای جاوا اسکریپت
Angular به عنوان یک فریمورک جاوا اسکریپت از کتابخانهها و ماژولهای متنوعی پشتیبانی میکند. با ترکیب این دو، میتوانید از کتابخانههای جاوا اسکریپت موجود در Angular بهره ببرید و قابلیتهای پیشرفتهتری را به اپلیکیشن خود اضافه کنید.
نتیجهگیری
استفاده از Blazor و Angular در پروژههای .NET Core به توسعهدهندگان این امکان را میدهد که از مزایای هر دو فریمورک بهرهبرداری کنند و اپلیکیشنهای وب پیچیده و تعاملی ایجاد کنند. این ترکیب میتواند به بهبود کیفیت کد، افزایش امنیت و ارائه تجربه کاربری بهتر منجر شود. همچنین، تفکیک مسئولیتها و استفاده از توانمندیهای موجود در هر دو فریمورک میتواند به توسعهدهندگان کمک کند تا اپلیکیشنهای مقیاسپذیر و قابل نگهداری ایجاد کنند.
مزایای استفاده از Blazor در پروژه های ASP.Net Core
استفاده از Blazor در پروژههای .NET Core مزایای زیادی دارد که به توسعهدهندگان کمک میکند تا اپلیکیشنهای وب تعاملی و قدرتمندی بسازند. در ادامه به بررسی مهمترین مزایای استفاده از Blazor میپردازیم:
- استفاده از C# به جای JavaScript
Blazor این امکان را فراهم میآورد که توسعهدهندگان از زبان C# به جای JavaScript برای نوشتن کد سمت کلاینت استفاده کنند. این امر به توسعهدهندگان .NET این امکان را میدهد که از مهارتهای موجود خود بهره ببرند و اپلیکیشنهای وب را بدون نیاز به یادگیری زبان جدید توسعه دهند.
- توسعه یکپارچه
با Blazor، میتوانید هم منطق سرور و هم منطق کلاینت را در یک پروژه و با یک زبان (C#) پیادهسازی کنید. این یکپارچگی باعث میشود که مدیریت پروژه و نگهداری کد آسانتر باشد.
- عملکرد بالا
Blazor WebAssembly به اپلیکیشنها این امکان را میدهد که به صورت کلاینت-ساید اجرا شوند و تجربه کاربری روانتری را فراهم کنند. این امر به کاهش تأخیر در بارگذاری و بهبود عملکرد اپلیکیشن کمک میکند.
- توسعه سریعتر با کامپوننتها
Blazor از الگوی کامپوننت استفاده میکند که به شما امکان میدهد اجزای قابل استفاده مجدد بسازید. این ویژگی باعث میشود که توسعهدهندگان بتوانند سرعت توسعه را افزایش دهند و از کدهای تکراری جلوگیری کنند.
- سازگاری با JavaScript
Blazor این امکان را فراهم میآورد که از کتابخانهها و کدهای JavaScript موجود در اپلیکیشن خود استفاده کنید. میتوانید با استفاده از JavaScript Interop به سادگی با کدهای جاوا اسکریپت ارتباط برقرار کنید و قابلیتهای پیشرفتهتری به اپلیکیشن اضافه کنید.
- امنیت و اعتبارسنجی
Blazor به خوبی با قابلیتهای امنیتی ASP.NET Core یکپارچه میشود و به شما این امکان را میدهد که از ویژگیهای امنیتی مانند هویت و دسترسی استفاده کنید. این قابلیت به افزایش امنیت اپلیکیشن کمک میکند.
- پشتیبانی از SPA (Single Page Application)
Blazor به راحتی میتواند به عنوان یک SPA توسعه یابد. این امر به کاربران تجربه کاربری بهتری میدهد و اپلیکیشن را سریعتر و پاسخگوتر میکند.
- تست آسانتر
با استفاده از C# برای نوشتن کد سمت کلاینت، میتوانید از ابزارهای تست واحد و یکپارچهسازی .NET برای تست کدهای خود استفاده کنید. این ویژگی به شما امکان میدهد تا به راحتی کیفیت کد را ارزیابی کنید.
- قابلیت نگهداری بالا
کدهای نوشته شده با Blazor معمولاً به دلیل استفاده از ساختار کامپوننتی و جداسازی منطق از UI، قابل نگهداریتر هستند. این امر به شما این امکان را میدهد که به سادگی اپلیکیشن خود را گسترش دهید و ویژگیهای جدیدی اضافه کنید.
- توسعه چندسکویی (Cross-platform)
Blazor امکان توسعه اپلیکیشنهای وب را برای پلتفرمهای مختلف (ویندوز، لینوکس، macOS فراهم میکند. این قابلیت به شما این امکان را میدهد که اپلیکیشنهای خود را به راحتی در محیطهای مختلف اجرا کنید.
- ارتباط آسان با APIها
Blazor به راحتی میتواند با APIهای RESTful ارتباط برقرار کند. این امر به شما این امکان را میدهد که دادهها را از سرور دریافت کرده و به راحتی در UI نمایش دهید.
- پشتیبانی از پکیجهای NuGet
Blazor از پکیجهای NuGet پشتیبانی میکند، به این معنی که میتوانید از کتابخانههای موجود در اکوسیستم .NET استفاده کنید و قابلیتهای جدیدی به اپلیکیشن خود اضافه کنید.
- اجزای تعاملی و واکنشگرا
Blazor امکان ایجاد اجزای تعاملی و واکنشگرا را فراهم میکند که به کاربران تجربه کاربری بهتری میدهد. این امر به توسعهدهندگان این امکان را میدهد که رابطهای کاربری جذاب و تعاملی طراحی کنند.
نتیجهگیری
استفاده از Blazor در پروژههای .NET Core به توسعهدهندگان این امکان را میدهد که اپلیکیشنهای وب مدرن و مقیاسپذیری ایجاد کنند که از مزایای زبان C# و اکوسیستم .NET بهرهبرداری میکنند. Blazor با قابلیتهای قدرتمند خود، توسعهدهندگان را قادر میسازد تا تجربه کاربری بهتری ارائه دهند و در عین حال توسعه و نگهداری اپلیکیشنها را آسانتر کنند.
معایب استفاده از String به جای StringBuilder در SqlCommand
استفاده از string به جای StringBuilder در ساخت دستورات SQL در SqlCommand میتواند معایبی داشته باشد که ممکن است روی کارایی و امنیت پروژههای شما تأثیر بگذارد. در ادامه به معایب اصلی این رویکرد پرداخته و به خطرات و مشکلات احتمالی آن اشاره میکنیم:
- کارایی پایین در عملیاتهای مکرر (Performance Issues)
String در C# یک نوع immutable است، به این معنی که هر تغییری روی آن باعث ایجاد یک نسخه جدید از رشته میشود. در زمانی که بخواهید یک دستور SQL پیچیده با تعداد زیادی پارامتر یا بخشهای الحاقی بسازید (مانند اضافه کردن فیلترها، شروط یا ستونها به صورت پویا)، استفاده از string باعث ایجاد چندین نسخه موقت از رشته میشود که منابع پردازشی و حافظه را مصرف میکند.
StringBuilder از سوی دیگر بهینهسازی شده است تا رشتهها را بدون نیاز به ایجاد نسخههای جدید تغییر دهد. به همین دلیل، در عملیاتهای طولانی یا زمانی که تعداد زیادی الحاق رشته انجام میدهید، استفاده از StringBuilder کارایی بهتری دارد.
- مستعد خطای امنیتی (SQL Injection)
وقتی از string برای ساختن دستورات SQL به صورت دستی استفاده میکنید، اگر مقادیر ورودی کاربر به صورت مستقیم به داخل رشته الحاق شوند، امکان SQL Injection وجود دارد. SQL Injection یک حمله بسیار متداول است که میتواند به هکر اجازه دهد تا دستورات SQL مخربی را به پایگاه داده ارسال کند.
StringBuilder نیز به خودی خود نمیتواند از SQL Injection جلوگیری کند، اما استفاده از پارامترهای SqlCommand مانند SqlParameter به جای الحاق رشتهها با string یا StringBuilder ، بهترین راه برای جلوگیری از این نوع حمله است.
- مدیریت دشوار دستورات طولانی
زمانی که با رشتههای طولانی و دستورات پیچیده SQL سروکار دارید، استفاده از string ممکن است باعث شود که کد شما کمتر قابل خواندن و مدیریت باشد. وقتی دستور SQL بزرگ است و نیاز به تنظیمات مختلف دارد، استفاده از StringBuilder برای سازماندهی و خواناتر کردن کد میتواند بهتر باشد.
StringBuilder به شما این امکان را میدهد که کد را در بخشهای منطقیتر و تمیزتر نوشته و مدیریت کنید، در حالی که استفاده از string و عملگر الحاق (+) میتواند به نوشتن کدهای طولانی و پیچیده منجر شود که دشوارتر برای نگهداری و رفع اشکال خواهد بود.
- مصرف بالاتر حافظه در موارد پیچیده
وقتی چندین الحاق رشته انجام میشود، string باعث ایجاد چندین نسخه از رشته در حافظه میشود که منابع بیشتری مصرف میکند. این مسئله در سناریوهایی که دادهها و دستورات SQL بزرگ هستند، میتواند باعث افزایش مصرف حافظه و کاهش عملکرد کلی اپلیکیشن شود.
StringBuilder از حافظه بهینهتری استفاده میکند، زیرا در صورت نیاز ظرفیت خود را افزایش میدهد و از ایجاد نسخههای متعدد جلوگیری میکند.
- کدهای پیچیدهتر در مدیریت الحاقهای چندگانه
با استفاده از string برای الحاق رشتهها، در مواردی که تعداد زیادی بخشهای مختلف برای ساختن دستور SQL دارید مثلاً شروط مختلف WHERE، فیلترهای داینامیک و غیره، مدیریت الحاق رشتهها میتواند دشوار و مستعد خطا باشد. این مشکل به خصوص زمانی دیده میشود که بخشهایی از دستورات SQL بر اساس شرایط مختلف به رشته اضافه میشوند.
با StringBuilder میتوان به راحتی بخشهای مختلف یک رشته را بدون نگرانی از تولید نسخههای موقت الحاق کرد و کد را تمیزتر و ساختیافتهتر نگه داشت.
- کاهش امنیت دادهها
هنگام استفاده از string برای ساخت دستورات SQL به صورت دستی، شما مستعد این هستید که دادههای حساس مانند نام کاربری یا رمز عبور را به صورت مستقیم در داخل رشته قرار دهید. این روش، به خصوص اگر به درستی از پارامترهای SQL استفاده نشود، میتواند امنیت دادهها را به خطر بیندازد.
با استفاده از پارامترهای امن در SqlCommand و اجتناب از الحاق رشتهها به صورت دستی، میتوان از این خطرات جلوگیری کرد.
- پیچیدگی در مدیریت فضای خالی و علائم نقل قول
یکی از چالشهای استفاده از string برای الحاق رشتههای SQL، مدیریت فضای خالی و علائم نقل قول است. به طور مثال، فراموش کردن اضافه کردن فاصله بین بخشهای مختلف یک دستور SQL یا درست نکردن نقل قولها برای مقادیر رشتهای، میتواند به خطاهای اجرای SQL منجر شود.
StringBuilder میتواند مدیریت بهتری روی این نوع مشکلات داشته باشد، چرا که به شما این امکان را میدهد که کد را در بخشهای مختلف و به صورت تدریجی بسازید و هر بخش به راحتی اضافه شود.
نتیجهگیری
استفاده از string در ساخت دستورات SQL با SqlCommand برای عملیاتهای ساده و کوچک مشکلی ایجاد نمیکند، اما در موارد پیچیدهتر یا هنگامی که نیاز به انجام الحاقهای مکرر و حجیم دارید، بهتر است از StringBuilder استفاده کنید تا کارایی بالاتر و مدیریت بهتری روی کد داشته باشید. همچنین، برای جلوگیری از مشکلات امنیتی مثل SQL Injection ، همیشه از پارامترهای SQL در SqlCommand به جای الحاق رشتهها استفاده کنید.
مزایای استفاده از recor به جای class در C# 12
استفاده از record به جای class در C# 12 مزایای زیادی دارد که به توسعهدهندگان کمک میکند تا کدهای بهینهتر و قابلمدیریتتری بنویسند. در اینجا به برخی از مهمترین مزایای استفاده از record نسبت به class اشاره میکنیم:
- Immutable بودن (غیرقابل تغییر) به طور پیشفرض
Record ها به طور پیشفرض غیرقابل تغییر هستند. این ویژگی به این معناست که پس از ایجاد یک شیء از نوع record، نمیتوانید مقادیر آن را تغییر دهید. این امر باعث افزایش ایمنی و جلوگیری از تغییرات ناخواسته در دادهها میشود.
البته میتوانید record های قابل تغییر (mutable) نیز تعریف کنید، اما در بیشتر موارد، غیرقابل تغییر بودن به حفظ یکپارچگی دادهها کمک میکند.
- سادهتر بودن ساختار
Record ها به سادگی میتوانند به عنوان انواع دادهای استفاده شوند و نیاز به نوشتن boilerplate code (کد تکراری) کمتری دارند. به طور مثال، شما به راحتی میتوانید پراپرتیها را با استفاده از ویژگیهای Auto-implemented properties و بدون نیاز به نوشتن getter و setterهای اضافی تعریف کنید.
- مقایسه سادهتر
مقایسه record ها به طور خودکار بر اساس مقادیر خاصیتها انجام میشود. این بدان معناست که دو شیء از نوع record با مقادیر یکسان به عنوان برابر (equal) در نظر گرفته میشوند. در حالی که برای class ها باید متد Equals را به طور دستی پیادهسازی کنید.
این ویژگی به سادگی به کد اجازه میدهد که مقایسهها را بدون نیاز به کدنویسی اضافی انجام دهد.
- قابلیت تجزیه و تحلیل (Deconstruction)
Record ها از قابلیت تجزیه و تحلیل پشتیبانی میکنند که به شما این امکان را میدهد تا به راحتی مقادیر خاصیتها را از یک شیء record استخراج کنید. این ویژگی میتواند در سناریوهای مختلفی مانند کار با tupleها و غیره مفید باشد.
- تعیین دادههای خودکار (Auto-Generated Data)
در record ها، میتوانید از ویژگیهای with-expressions برای ایجاد کپیهای جدید با تغییر در برخی مقادیر استفاده کنید. به این ترتیب، میتوانید به سادگی یک شیء جدید ایجاد کنید که تعدادی از ویژگیها را حفظ کند و فقط ویژگیهای مورد نیاز را تغییر دهد.
- کدهای تمیزتر و قابلخواندنتر
استفاده از recordها معمولاً منجر به کدهای تمیزتر و قابلخواندنتری میشود، زیرا به شما اجازه میدهند تا به سادگی مقادیر را تعریف کنید و به طور پیشفرض با ویژگیهای خوب C# از جمله Deconstruction و with-expressions کار کنید.
- استفاده از تابع ToString به طور خودکار
برای recordها متد ToString به طور خودکار ایجاد میشود تا نمایشی از دادهها را به شکل متن ارائه دهد. این ویژگی به شما این امکان را میدهد که به راحتی اطلاعات را در هنگام دیباگ کردن یا در هنگام لاگگذاری مشاهده کنید.
- پشتیبانی از الگوی کد (Pattern Matching)
Record ها از الگوی کد (pattern matching) به خوبی پشتیبانی میکنند، که به شما این امکان را میدهد که به سادگی بررسی کنید که آیا یک شیء خاص از نوع record خاصی است یا خیر. این ویژگی میتواند در نوشتن کدهای شرطی و پیچیده کمک کننده باشد.
- پشتیبانی از پراپرتیهای محاسباتی (Computed Properties)
میتوانید در record ها پراپرتیهایی تعریف کنید که بر اساس سایر پراپرتیها محاسبه میشوند. این ویژگی به سادگی و بهینهسازی کد کمک میکند.
- تسهیل در کار با DTOها (Data Transfer Objects)
Record ها به طور خاص برای سناریوهای DTO طراحی شدهاند. شما میتوانید به راحتی دادهها را منتقل کنید و از ویژگیهای آنها به عنوان ورودی و خروجی در APIها و دیگر بخشهای برنامه استفاده کنید.
- کاهش خطای انسانی
با توجه به اینکه recordها به طور خودکار متدهای مورد نیاز را برای مقایسه و تولید متن فراهم میکنند، این امر منجر به کاهش خطاهای انسانی ناشی از کدنویسی دستی میشود.
نتیجهگیری
استفاده از record به جای class در C# 12 میتواند مزایای زیادی برای توسعهدهندگان داشته باشد، به ویژه در زمینه کار با دادهها و ساختارهای اطلاعاتی. ویژگیهایی نظیر غیرقابل تغییر بودن، مقایسه آسان، قابلیت تجزیه و تحلیل و کدهای تمیزتر، باعث میشود که record انتخاب بهتری برای بسیاری از سناریوها باشد، به ویژه در پروژههای مبتنی بر داده.
آیا recorها reference type هستند؟
بله، record در C# یک نوع مرجع (reference type) است. در واقع، recordها نوعی خاص از کلاسها هستند که برای نمایندگی دادهها و ایجاد انواع دادهای با ویژگیهای خاص طراحی شدهاند.
نکات کلیدی درباره record ها:
نوع مرجع (Reference Type) :
مانند کلاسها، record ها نیز به عنوان نوع مرجع شناخته میشوند. به این معنا که وقتی یک شیء از نوع record ایجاد میکنید، در واقع یک مرجع به آن شیء در حافظه ایجاد میشود و نه یک کپی واقعی از آن. اگر چندین متغیر به یک شیء record اشاره کنند، تغییر در یکی از این متغیرها میتواند بر روی دیگر متغیرها تأثیر بگذارد.
غیرقابل تغییر (Immutable) به طور پیشفرض:
Record ها به طور پیشفرض غیرقابل تغییر هستند. به این معنی که پس از ایجاد، نمیتوانید مقادیر ویژگیهای آنها را تغییر دهید. اگر بخواهید ویژگیها را تغییر دهید، باید از with-expressions برای ایجاد یک شیء جدید استفاده کنید.
مقایسه بر اساس مقادیر:
مقایسه record ها به طور خودکار بر اساس مقادیر ویژگیها انجام میشود، نه بر اساس مرجع. این ویژگی باعث میشود که دو شیء از نوع record با مقادیر مشابه به عنوان برابر در نظر گرفته شوند.
استفاده در مدلهای داده:
به دلیل طراحی ساده و قابلیتهای خوب آنها، recordها معمولاً در طراحی DTOها (Data Transfer Objects) و مدلهای داده استفاده میشوند.
نتیجهگیری
در مجموع، record ها به عنوان نوع مرجع به شما این امکان را میدهند که دادهها را به شیوهای سازمانیافته و مؤثر مدیریت کنید، در حالی که از ویژگیهای مفیدی مانند مقایسه بر اساس مقادیر و غیرقابل تغییر بودن بهرهمند میشوید.
بهترین performance را recor دارد یا class ؟
در C#، انتخاب بین record و class به ویژه در زمینه عملکرد به نیازهای خاص شما و نوع استفاده از دادهها بستگی دارد. در زیر برخی از نکات کلیدی در مورد عملکرد record و class آورده شده است:
- غیرقابل تغییر بودن (Immutability)
Record ها به طور پیشفرض غیرقابل تغییر هستند، به این معنی که پس از ایجاد یک شیء record، نمیتوانید مقادیر آن را تغییر دهید. این ویژگی میتواند منجر به بهبود عملکرد در سناریوهایی شود که از دادهها به صورت خواندنی استفاده میشود، زیرا نیازی به ایجاد کپیهای متعدد از دادهها نیست.
از طرفی، class ها میتوانند قابل تغییر یا غیرقابل تغییر باشند. اگر یک class به عنوان قابل تغییر (mutable) تعریف شده باشد، ممکن است در طول عمر خود به تغییرات متعددی نیاز داشته باشد که میتواند عملکرد را تحت تأثیر قرار دهد.
- مقایسه و برابری (Equality Comparison)
در record ها، مقایسه به طور خودکار بر اساس مقادیر ویژگیها انجام میشود، که این کار را ساده و سریع میکند. این نوع مقایسه میتواند در سناریوهایی که نیاز به مقایسه تعداد زیادی از اشیاء وجود دارد، عملکرد را بهبود بخشد.
در class ها، برای مقایسه اشیاء باید متد Equals و GetHashCode را به طور دستی پیادهسازی کنید که این کار میتواند پیچیدهتر و زمانبر باشد.
- استفاده از حافظه (Memory Usage)
Record ها به دلیل طراحی خاصشان، معمولاً از نظر استفاده از حافظه بهینهتر هستند. به عنوان مثال، اگر شما بخواهید چندین شیء مشابه از یک record داشته باشید، میتوانید از قابلیتهای مانند with-expressions برای ایجاد نسخههای جدید بدون نیاز به کپیهای اضافی استفاده کنید.
Class ها ممکن است برای اشیاء مشابه به کپیهای کامل نیاز داشته باشند، که این امر میتواند مصرف حافظه را افزایش دهد.
- تجزیه و تحلیل (Deconstruction)
Record ها از قابلیت تجزیه و تحلیل پشتیبانی میکنند که میتواند عملکرد را در مواقعی که نیاز به استخراج دادهها از یک شیء دارید، بهبود بخشد.
این ویژگی ممکن است به طور مستقیم در class ها وجود نداشته باشد و نیاز به کدهای اضافی برای پیادهسازی آن باشد.
- سازگاری و خوانایی کد
استفاده از record میتواند به ایجاد کدهای خوانا و تمیزتر منجر شود. این امر میتواند به کاهش زمان توسعه و اشکالزدایی کمک کند و در نهایت منجر به عملکرد بهتر کلی پروژه شود.
- بهینهسازیهای کامپایلر
در C# 12، record ها ممکن است بهینهسازیهای خاصی از سوی کامپایلر بهرهمند شوند که میتواند به بهبود عملکرد منجر شود.
نتیجهگیری
در نهایت، اگرچه record ها به طور خاص طراحی شدهاند تا به عنوان انواع دادهای با کارایی بالا عمل کنند و در بسیاری از سناریوها عملکرد بهتری نسبت به class ها داشته باشند، اما انتخاب بین این دو به نیازهای خاص شما و نحوه استفاده از دادهها بستگی دارد. اگر پروژه شما به ویژگیهای record ها مانند غیرقابل تغییر بودن و مقایسه آسان نیاز دارد، انتخاب record ممکن است بهترین گزینه باشد. اما اگر نیاز به طراحیهای پیچیدهتر یا متغیرهای قابل تغییر دارید، class ممکن است مناسبتر باشد.
بهترین performance را record دارد یا calss یا struct و برای dto ها کدام را انتخاب کنیم و چرا؟
انتخاب بین record ، class و struct برای DTOها (Data Transfer Objects) در C# به نیازها و شرایط خاص پروژه شما بستگی دارد. در زیر، به مقایسه این سه نوع داده از نظر عملکرد و مناسب بودن برای DTOها میپردازیم.
- record
عملکرد:
Record ها به عنوان نوع مرجع عمل میکنند و به طور پیشفرض غیرقابل تغییر (immutable) هستند. این ویژگی میتواند منجر به بهبود کارایی در سناریوهایی شود که شما فقط دادهها را میخوانید و نیازی به تغییر آنها ندارید.
مقایسه record ها بر اساس مقادیر خاصیتها انجام میشود، که این کار را سریعتر و سادهتر میکند.
مناسب بودن برای DTOها:
به دلیل ویژگیهای غیرقابل تغییر بودن، مقایسه آسان و قابلیت تجزیه و تحلیل، record ها معمولاً برای DTOها مناسب هستند. این ویژگیها میتوانند به شما کمک کنند تا دادهها را به شکل ساده و خوانا انتقال دهید.
- class
عملکرد:
Class ها نیز نوع مرجع هستند، اما معمولاً قابل تغییر (mutable) هستند. این بدان معناست که میتوانید مقادیر ویژگیها را پس از ایجاد شیء تغییر دهید.
برای مقایسه اشیاء از class ها، شما باید متدهای Equals و GetHashCode را به طور دستی پیادهسازی کنید که میتواند زمانبر باشد.
مناسب بودن برای DTOها:
Class ها میتوانند برای DTOها مناسب باشند، به ویژه اگر نیاز به تغییر مقادیر دادهها در طول عمر شیء دارید. با این حال، اگر از class ها استفاده میکنید، باید توجه داشته باشید که پیچیدگی بیشتری در مقایسه و مدیریت دادهها وجود خواهد داشت.
- struct
عملکرد:
Struct ها نوع مقدار (value type) هستند و به این معنی است که مقادیر آنها به طور مستقیم ذخیره میشوند. این میتواند منجر به کارایی بهتر در برخی سناریوها شود، به ویژه هنگامی که مقادیر کوچک و ساده هستند.
اما struct ها به دلیل ویژگیهای غیرقابل تغییر بودن و نداشتن قابلیت مقایسه آسان میتوانند در سناریوهای پیچیدهتر به مشکلاتی بر بخورند.
مناسب بودن برای DTOها:
به طور کلی، struct ها برای DTOها توصیه نمیشوند، زیرا معمولاً برای انتقال دادههای بزرگ یا پیچیده استفاده نمیشوند و میتوانند مشکلاتی از قبیل کپیهای غیرمنتظره و نادرستی در مقایسه ایجاد کنند. همچنین، رفتار غیرقابل تغییر آنها ممکن است مدیریت دادهها را دشوار کند.
نتیجهگیری
برای DTO ها، record ها معمولاً بهترین گزینه هستند، به ویژه اگر شما به دنبال ساختارهای دادهای ساده و مؤثر هستید. ویژگیهای غیرقابل تغییر بودن، مقایسه آسان و تجزیه و تحلیل آنها به شما کمک میکند تا دادهها را به راحتی مدیریت و منتقل کنید.
اگر نیاز به تغییر مقادیر در طول عمر شیء دارید یا از دادههای پیچیدهتری استفاده میکنید، میتوانید از class ها استفاده کنید.
Struct ها معمولاً برای سناریوهای DTO مناسب نیستند و بهتر است برای انواع دادهای ساده و کوچک مورد استفاده قرار گیرند.
در نهایت، انتخاب بین این سه نوع به نیازهای خاص پروژه، پیچیدگی دادهها و نحوه استفاده از آنها بستگی دارد.
تفاوت jwt و reference در access_token
تفاوت اصلی بین JWT (JSON Web Token) و Reference Token در استفاده و نحوه اعتبارسنجی توکنها در سیستمهای احراز هویت و مجوز (authentication and authorization) است. در زیر به تفصیل این دو نوع توکن و تفاوتهای آنها میپردازیم:
- JWT (JSON Web Token)
ساختار:
JWT یک توکن مستقل است که شامل سه بخش اصلی است:
Header: اطلاعاتی درباره نوع توکن و الگوریتم رمزنگاری.
Payload: حاوی دادههای مرتبط (claims) مانند اطلاعات کاربر و زمان انقضا.
Signature: یک امضا برای تایید صحت توکن.
ویژگیها:
استقلال: توکن JWT به طور کامل اطلاعات مورد نیاز برای اعتبارسنجی خود را درون خود دارد. بنابراین، نیازی به ذخیرهسازی در سمت سرور نیست.
قابلیت انتقال: به دلیل ساختار JSON، JWT به راحتی در سیستمهای مختلف و بین سرورها قابل استفاده است.
سازگاری: JWT ها معمولاً در APIها و سرویسهای میکروسرویس استفاده میشوند و میتوانند به راحتی در دیگر زبانهای برنامهنویسی و پلتفرمها مورد استفاده قرار گیرند.
معایب:
حجم: به دلیل محتوای اضافی Header و Payload، حجم JWT معمولاً بزرگتر از توکنهای مرجع است.
امنیت: اگرچه JWTها رمزنگاری شدهاند، اما اگر توکن به سرقت برود، فرد مهاجم میتواند به دادههای آن دسترسی داشته باشد تا زمانی که توکن منقضی شود.
- Reference Token
ساختار:
Reference Token به طور کلی یک شناسه یکتا (ID) است که به توکن نسبت داده میشود و به طور مستقیم به اطلاعات در سرور احراز هویت مرتبط است. به جای اینکه اطلاعات در خود توکن ذخیره شود، این اطلاعات در سرور نگهداری میشود.
ویژگیها:
ذخیرهسازی: توکنهای مرجع در سمت سرور ذخیره میشوند و به هنگام درخواست، سرور میتواند اعتبار توکن را بررسی کند.
مدیریت آسان: امکان لغو (revocation) توکنها به راحتی وجود دارد، زیرا سرور میتواند توکن را در هر زمان از بین ببرد.
کاهش حجم: حجم Reference Tokenها معمولاً کمتر از JWTها است زیرا فقط یک شناسه یکتا را ارسال میکنند.
معایب:
وابستگی به سرور: برای اعتبارسنجی توکن، هر بار نیاز به تماس با سرور است. این امر میتواند عملکرد را تحت تأثیر قرار دهد و در مقیاسهای بزرگتر، ایجاد یک گلوگاه شود.
قابلیت انتقال محدود: به دلیل وابستگی به سرور، استفاده از Reference Tokenها در محیطهای میکروسرویس و توزیع شده ممکن است دشوارتر باشد.
نتیجهگیری
JWT برای سیستمهایی که نیاز به مقیاسپذیری و مستقل بودن دارند، مناسبتر است. همچنین، اگر توکنها به صورت مکرر مورد استفاده قرار میگیرند و نیاز به مدیریت کمتر دارند، JWT انتخاب خوبی است.
Reference Token برای سیستمهایی که نیاز به مدیریت دقیق و امنیت بیشتری دارند، مانند زمانی که میخواهید توکنها را به راحتی لغو کنید، مناسبتر است.
در نهایت، انتخاب بین JWT و Reference Token به نیازهای خاص پروژه، امنیت و مقیاسپذیری بستگی دارد.
مزایا و نحوه استفاده از ElasticSearch در ASP.Net core
Elasticsearch یک موتور جستجوی توزیعشده و قدرتمند است که برای جستجوی سریع و تحلیل دادهها استفاده میشود. در ASP.NET Core، میتوانید از Elasticsearch برای بهبود قابلیت جستجو و پردازش دادهها در برنامههای خود استفاده کنید. در زیر به مزایا و نحوه استفاده از Elasticsearch در ASP.NET Core میپردازیم.
مزایای استفاده از Elasticsearch
جستجوی سریع و قدرتمند:
Elasticsearch بهطور خاص برای جستجو بهینه شده است و میتواند جستجوهای پیچیده را به سرعت انجام دهد. این قابلیت به ویژه برای برنامه هایی که نیاز به جستجوی متنی، فیلتر کردن و مرتبسازی دارند، بسیار مفید است.
تحلیل دادهها:
Elasticsearch قابلیتهای تحلیل دادهها را نیز ارائه میدهد، که به شما امکان میدهد اطلاعاتی درباره الگوها و روندها در دادههای خود به دست آورید. این ویژگی به ویژه در تجزیه و تحلیل لاگها و دادههای بزرگ بسیار کاربردی است.
مقیاسپذیری:
Elasticsearch به صورت توزیعشده طراحی شده است و به راحتی میتوان آن را به مقیاسهای بزرگتر گسترش داد. این ویژگی باعث میشود تا Elasticsearch برای برنامههای با حجم بالای داده مناسب باشد.
انعطافپذیری:
Elasticsearch از JSON به عنوان فرمت داده استفاده میکند و این امکان را میدهد تا انواع مختلفی از دادهها را ذخیره و جستجو کنید. همچنین، شما میتوانید ساختارهای داده خود را به راحتی تغییر دهید.
نظارت و تحلیل لاگها:
بهطور معمول، Elasticsearch به همراه Kibana برای نظارت و تحلیل لاگها استفاده میشود. این ترکیب میتواند به شما در تحلیل و تجسم دادههای خود کمک کند.
پشتیبانی از جستجوی پیشرفته:
Elasticsearch از قابلیتهای جستجوی پیشرفتهای مانند fuzzy search، جستجوی نزدیک و جستجوی زمینهای (faceted search) پشتیبانی میکند.
نحوه استفاده از Elasticsearch در ASP.NET Core
برای استفاده از Elasticsearch در ASP.NET Core، مراحل زیر را دنبال کنید:
- نصب بستههای مورد نیاز
ابتدا باید بسته NEST را نصب کنید. این بسته یک کلاینت C# برای Elasticsearch است.
dotnet add package NEST
- تنظیم Elasticsearch
در فایل appsettings.json، پیکربندی اتصال به Elasticsearch را اضافه کنید:
{
"ElasticSearch": {
"Url": "http://localhost:9200",
"DefaultIndex": "your_default_index"
}
}- ایجاد کلاس Startup
در کلاس Startup، تنظیمات Elasticsearch را در متد ConfigureServices اضافه کنید:
public void ConfigureServices(IServiceCollection services)
{
// سایر تنظیمات...
var settings = new ConnectionSettings(new Uri(Configuration["ElasticSearch:Url"]))
.DefaultIndex(Configuration["ElasticSearch:DefaultIndex"]);
var client = new ElasticClient(settings);
services.AddSingleton(client);
}- استفاده از Elasticsearch در کنترلرها یا سرویسها
حالا میتوانید از کلاینت Elasticsearch در کنترلرها یا سرویسهای خود استفاده کنید. به عنوان مثال:
[ApiController]
[Route("[controller]")]
public class SearchController : ControllerBase
{
private readonly ElasticClient _elasticClient;
public SearchController(ElasticClient elasticClient)
{
_elasticClient = elasticClient;
}
[HttpGet]
public async Task<IActionResult> Search(string query)
{
var response = await _elasticClient.SearchAsync<YourDocumentType>(s => s
.Index("your_index_name")
.Query(q => q
.Match(m => m
.Field(f => f.YourField)
.Query(query)
)
)
);
return Ok(response.Documents);
}
}- ایندکسکردن دادهها
برای ایندکسکردن دادهها، میتوانید از متد IndexDocumentAsync استفاده کنید:
var document = new YourDocumentType
{
// مقداردهی به ویژگیها
};
var indexResponse = await _elasticClient.IndexDocumentAsync(document);نتیجهگیری
استفاده از Elasticsearch در ASP.NET Core میتواند به شما کمک کند تا قابلیتهای جستجوی پیشرفته، تجزیه و تحلیل دادهها و مقیاسپذیری را به برنامههای خود اضافه کنید. با توجه به مزایای بالای آن، Elasticsearch گزینهای عالی برای پروژههای بزرگ و پیچیده است.
فرق بین Abstract و interface در Asp.Net Core چیست؟
در ASP.NET Core (و به طور کلی در زبان C#)، abstract class و interface دو روش برای تعریف قراردادها یا قواعدی هستند که سایر کلاسها باید پیروی کنند، اما تفاوتهایی بین آنها وجود دارد:
1. Abstract Class (کلاس انتزاعی)
یک کلاس انتزاعی، یک نوع کلاس است که میتواند حاوی متدهای تعریف نشده (abstract methods) باشد که پیادهسازی آنها به عهده کلاسهای فرزند است، و همچنین میتواند شامل متدهای پیادهسازی شده (concrete methods) نیز باشد.
ویژگیها:
- میتواند فیلدها (fields)، سازندهها (constructors)، متغیرهای ثابت (constants)، و متدهای تعریف شده داشته باشد.
- میتواند حاوی متدهای انتزاعی (بدون پیادهسازی) و غیرانتزاعی (با پیادهسازی) باشد.
- کلاسهای فرزند باید تمام متدهای انتزاعی را پیادهسازی کنند، اما میتوانند متدهای غیرانتزاعی را هم فراخوانی کنند یا تغییر دهند.
- از ارثبری (inheritance) استفاده میکند، یعنی هر کلاس فقط میتواند از یک کلاس انتزاعی ارثبری کند.
مثال:
public abstract class Animal
{
public abstract void MakeSound(); // متد انتزاعی بدون پیادهسازی
public void Sleep() // متد غیرانتزاعی با پیادهسازی
{
Console.WriteLine("Sleeping...");
}
}
public class Dog : Animal
{
public override void MakeSound()
{
Console.WriteLine("Bark!");
}
}2. Interface (رابط)
یک اینترفیس مجموعهای از امضاهای متدها، خصوصیات (properties)، رویدادها (events)، یا ایندکسرها (indexers) را تعریف میکند. اینترفیس هیچ پیادهسازیای ندارد و کلاسها یا ساختارها باید تمام اعضای آن را پیادهسازی کنند.
ویژگیها:
- نمیتواند فیلدها، سازندهها یا متغیرهای ثابت داشته باشد (البته در C# 8.0 به بعد، امکان پیادهسازی پیشفرض متدها در اینترفیس وجود دارد).
- همه متدهای اینترفیس بدون پیادهسازی هستند (البته با C# 8.0 به بعد، میتوانید پیادهسازی پیشفرض داشته باشید).
- یک کلاس یا ساختار میتواند چندین اینترفیس را پیادهسازی کند (multiple inheritance).
مثال:
public interface IAnimal
{
void MakeSound();
}
public class Dog : IAnimal
{
public void MakeSound()
{
Console.WriteLine("Bark!");
}
}
تفاوتهای کلیدی:
- ارثبری:
- کلاسهای انتزاعی از ارثبری تکگانه (single inheritance) استفاده میکنند، یعنی یک کلاس فقط میتواند از یک کلاس انتزاعی ارثبری کند.
- اینترفیسها از ارثبری چندگانه (multiple inheritance) استفاده میکنند، یعنی یک کلاس میتواند چندین اینترفیس را پیادهسازی کند.
- پیادهسازی:
- کلاس انتزاعی میتواند متدهایی با پیادهسازی ارائه دهد.
- اینترفیسها (در نسخههای قدیمیتر C#) فقط امضای متدها را دارند و هیچ پیادهسازی ندارند (هرچند C# 8.0 به بعد اجازه پیادهسازی پیشفرض را میدهد).
- فیلدها و سازندهها:
- کلاس انتزاعی میتواند فیلدها و سازندهها داشته باشد.
- اینترفیسها نمیتوانند فیلد یا سازنده داشته باشند.
- کاربرد:
- از کلاسهای انتزاعی زمانی استفاده میشود که نیاز به پیادهسازی پیشفرض یا اشتراکگذاری کد بین چندین کلاس دارید.
- از اینترفیسها زمانی استفاده میشود که فقط میخواهید یک قرارداد را تعریف کنید و پیادهسازی کلاً بر عهده کلاسها باشد.
کدامیک را استفاده کنیم؟
- اگر نیاز دارید بخشی از پیادهسازیها را در یک کلاس پایه به اشتراک بگذارید، از abstract class استفاده کنید.
- اگر فقط میخواهید مطمئن شوید که کلاسها یک مجموعه خاص از متدها را پیادهسازی میکنند، از interface استفاده کنید.
تفاوت AddScope() و AddTransient() و AddSingleton() در ثبت سرویسها در DI (Dependency Injection) در ASP.Net Core
در ASP.NET Core، سه روش اصلی برای ثبت سرویسها در DI (Dependency Injection) وجود دارد که هرکدام چرخه عمر متفاوتی دارند. این سه روش عبارتاند از: AddScoped()، AddTransient() و AddSingleton(). تفاوتهای کلیدی بین این سه روش مربوط به نحوه مدیریت چرخه زندگی (Lifetime) اشیاء سرویسها است.
1. AddScoped()
این متد برای ثبت سرویسهایی استفاده میشود که طول عمر آنها به مدت زمان یک درخواست HTTP است. به عبارت دیگر، یک نمونه (instance) از سرویس برای هر درخواست ساخته میشود و در طول آن درخواست به اشتراک گذاشته میشود.
- برای هر درخواست HTTP یک نمونه جدید از سرویس ساخته میشود.
- در طول یک درخواست خاص، اگر سرویس چندین بار تزریق شود، همه جا همان نمونه مشترک استفاده خواهد شد.
کاربرد: زمانی استفاده میشود که نیاز دارید داده یا وضعیت را در طول یک درخواست HTTP به اشتراک بگذارید، اما نمیخواهید دادهها بین درخواستهای مختلف مشترک باشند (مثلاً برای DbContext).
مثال:
services.AddScoped<IMyService, MyService>();
2. AddTransient()
این متد برای ثبت سرویسهایی استفاده میشود که طول عمر آنها بسیار کوتاه است. هر بار که این سرویس درخواست میشود، یک نمونه جدید ساخته میشود.
- هر بار که سرویس نیاز است (در هر injection)، یک نمونه جدید ساخته میشود.
- مناسب برای سرویسهایی که سبک هستند و به نگهداری وضعیت نیاز ندارند.
کاربرد: برای سرویسهایی که هیچ نیازی به اشتراکگذاری داده بین درخواستها یا بین کلاسها ندارند و سبک هستند. به عنوان مثال، سرویسهایی که منطق سادهای دارند و وضعیت داخلی نگهداری نمیکنند.
مثال:
services.AddTransient<IMyService, MyService>();
3. AddSingleton()
این متد برای ثبت سرویسهایی استفاده میشود که طول عمر آنها به مدت زمان کل چرخه حیات برنامه است. یک نمونه از سرویس ساخته میشود و در کل عمر برنامه به اشتراک گذاشته میشود.
- یک نمونه از سرویس هنگام شروع برنامه ایجاد میشود و همان نمونه در سراسر برنامه استفاده میشود.
- مناسب برای سرویسهایی که نیازی به تغییر داده یا وضعیت در طول زمان ندارند.
کاربرد: برای سرویسهایی که سنگین هستند و بهتر است فقط یک بار ساخته شوند (مثلاً سرویسهایی که منابع زیادی استفاده میکنند، مانند memory cache).
مثال:
services.AddSingleton<IMyService, MyService>();
خلاصه تفاوتها:
| متد | طول عمر (Lifetime) | ایجاد نمونهها | کاربرد اصلی |
|---|---|---|---|
AddScoped() | در طول هر درخواست HTTP | یک نمونه جدید برای هر درخواست HTTP و استفاده مکرر در آن درخواست | اشتراکگذاری داده در طول درخواست HTTP |
AddTransient() | کوتاه مدت (هر بار که نیاز باشد) | هر بار که سرویس تزریق میشود، یک نمونه جدید ساخته میشود | سرویسهای سبک که وضعیت داخلی ندارند |
AddSingleton() | طول عمر برنامه | یک نمونه در کل عمر برنامه ایجاد و به اشتراک گذاشته میشود | سرویسهای سنگین یا سرویسهای بدون تغییر |
نکته مهم:
انتخاب نوع سرویس بر اساس نحوه استفاده و نیازهای پروژه انجام میشود. به عنوان مثال:
- برای DbContext، معمولاً از
AddScoped()استفاده میشود زیرا هر درخواست HTTP به یک کانکشن دیتابیس نیاز دارد که نباید بین درخواستها به اشتراک گذاشته شود. - برای سرویسهای logging، از
AddSingleton()استفاده میشود، زیرا سرویس لاگینگ نیازی به ایجاد مجدد در هر درخواست ندارد. - برای سرویسهای سبک، مانند فرمت کنندههای داده یا محاسبات کوچک، از
AddTransient()استفاده میشود تا از سربار اضافی جلوگیری شود.
تفاوت AsNoTracker با Tracker در Entity Framework (EF)
در Entity Framework (EF)، دو حالت ردیابی (tracking) و عدم ردیابی (no-tracking) برای مدیریت دادهها وجود دارد. این حالتها با استفاده از متدهایی مانند AsNoTracking و پیشفرضهای ردیابی انجام میشوند. درک تفاوت این دو حالت به بهبود کارایی و مدیریت منابع در پروژه کمک میکند.
1. AsNoTracking()
وقتی از AsNoTracking() استفاده میکنید، EF دادههای بازگشتی را ردیابی نمیکند. این بدان معناست که پس از واکشی (query) دادهها از پایگاه داده، EF وضعیت آنها را برای تغییرات احتمالی نگهداری نمیکند. بنابراین، اگر تغییراتی در این موجودیتها ایجاد شود، EF این تغییرات را متوجه نمیشود و آنها را در پایگاه داده ذخیره نخواهد کرد مگر اینکه بهطور صریح از Update() یا Attach() استفاده کنید.
ویژگیها:
- بدون ردیابی: EF هیچ تغییری را روی دادههای واکشیشده دنبال نمیکند.
- عملکرد بهتر: به دلیل عدم نیاز به ردیابی وضعیت دادهها، عملیات جستجو سریعتر انجام میشود.
- صرفهجویی در منابع حافظه: منابع حافظه کمتری مصرف میشود چون EF نیازی به ذخیره وضعیت اشیاء ندارد.
- مناسب برای عملیات خواندنی: این حالت معمولاً برای کوئریهایی که فقط برای خواندن دادهها استفاده میشوند، مفید است (مثلاً وقتی که نیازی به تغییر و بهروزرسانی دادهها ندارید).
مثال:
var customers = context.Customers.AsNoTracking().ToList();
در این مثال، هیچ یک از مشتریانی که بازگشت داده میشوند، توسط EF ردیابی نخواهند شد.
2. Tracking (ردیابی)
در حالت پیشفرض (بدون AsNoTracking())، EF بهطور خودکار دادههای واکشیشده از پایگاه داده را ردیابی میکند. این یعنی، EF وضعیت فعلی موجودیتها را نگهداری میکند و هرگونه تغییرات در این موجودیتها را دنبال میکند. سپس زمانی که عملیات ذخیرهسازی (مثلاً SaveChanges()) فراخوانی میشود، EF این تغییرات را شناسایی کرده و به پایگاه داده اعمال میکند.
ویژگیها:
- ردیابی کامل موجودیتها: هر زمان که موجودیتی از پایگاه داده واکشی میشود، EF وضعیت آن را در حافظه نگه میدارد.
- مناسب برای عملیات CRUD: این حالت زمانی مناسب است که بخواهید دادههای واکشیشده را تغییر دهید و آنها را در پایگاه داده ذخیره کنید.
- استفاده بیشتر از منابع حافظه: از آنجا که EF وضعیت تمام موجودیتها را در حافظه نگه میدارد، در مقایسه با
AsNoTrackingمصرف منابع حافظه و CPU بیشتر است.
مثال:
var customers = context.Customers.ToList();
customers[0].Name = "Updated Name";
context.SaveChanges(); // تغییرات در پایگاه داده اعمال میشوددر این مثال، EF مشتریها را ردیابی میکند، و پس از تغییر نام مشتری اول، هنگام فراخوانی SaveChanges() تغییرات در پایگاه داده ذخیره میشوند.
خلاصه تفاوتها:
| ویژگی | Tracking (پیشفرض) | AsNoTracking() |
|---|---|---|
| ردیابی تغییرات | بله، EF تغییرات موجودیتها را دنبال میکند | خیر، EF هیچ تغییری را ردیابی نمیکند |
| عملکرد | کندتر به دلیل ردیابی تغییرات | سریعتر به دلیل عدم ردیابی |
| مصرف منابع حافظه | بیشتر، چون EF باید وضعیت موجودیتها را نگه دارد | کمتر، چون نیازی به نگهداری وضعیت نیست |
| مناسب برای | عملیاتهای CRUD (خواندن/نوشتن/بهروزرسانی) | عملیاتهای فقط خواندنی |
کی باید از AsNoTracking استفاده کنیم؟
- برای کوئریهای فقط خواندنی: اگر نیازی به تغییر دادهها ندارید، بهتر است از
AsNoTracking()استفاده کنید تا بهبود عملکرد و کاهش مصرف حافظه را تجربه کنید. - زمانی که دادهها را فقط نمایش میدهید: مثلاً در صفحات گزارشها یا نمایش دادههای لیستی،
AsNoTracking()گزینه مناسبی است.
کی باید از ردیابی استفاده کنیم؟
- برای عملیاتهای CRUD: اگر قصد دارید بعد از واکشی دادهها، آنها را تغییر دهید و سپس ذخیره کنید، باید از حالت ردیابی پیشفرض استفاده کنید تا EF بتواند این تغییرات را شناسایی و به پایگاه داده اعمال کند.
استفاده بهینه از این دو حالت میتواند به بهبود عملکرد کلی برنامه شما کمک کند، بهخصوص در پروژههای بزرگ و دارای حجم بالای داده.
فرق First() و FirstOrDefault() و Single() و SingleOrDefault() در Entity Framework(EF)
در Entity Framework (EF)، متدهای First()، FirstOrDefault()، Single()، و SingleOrDefault() برای جستجوی رکوردهای خاص در یک مجموعه داده (مثلاً یک جدول) استفاده میشوند. این متدها از لحاظ نحوه بازگرداندن رکوردها و مدیریت خطاها در صورت یافتن تعداد بیشتر یا کمتر از انتظار تفاوتهایی دارند.
1. First()
متد First() اولین رکوردی که با شرط مشخص شده مطابقت دارد را از مجموعه باز میگرداند. اگر هیچ رکوردی پیدا نشود، یک استثنا (Exception) ایجاد میشود.
ویژگیها:
- اولین رکورد مطابق با شرط را بازمیگرداند.
- اگر رکوردی پیدا نشود، یک استثنای
InvalidOperationExceptionرخ میدهد. - مناسب برای زمانی که میدانید حداقل یک رکورد وجود دارد.
مثال:
var customer = context.Customers.First(c => c.Name == "John");
در این مثال، اگر مشتری با نام “John” وجود داشته باشد، اولین مورد بازگردانده میشود؛ در غیر این صورت، یک استثنا رخ میدهد.
2. FirstOrDefault()
متد FirstOrDefault() مشابه First() است، با این تفاوت که اگر هیچ رکوردی پیدا نشود، به جای ایجاد استثنا، مقدار پیشفرض (که برای مرجعها null و برای انواع مقداری ۰ یا false است) باز میگرداند.
ویژگیها:
- اولین رکورد مطابق با شرط را بازمیگرداند.
- اگر رکوردی پیدا نشود، مقدار پیشفرض (معمولاً
null) بازمیگردد. - مناسب برای زمانی که ممکن است هیچ رکوردی مطابق با شرط وجود نداشته باشد و میخواهید از استثنا جلوگیری کنید.
مثال:
var customer = context.Customers.FirstOrDefault(c => c.Name == "John");
در این مثال، اگر مشتری با نام “John” وجود نداشته باشد، مقدار null بازگردانده میشود.
3. Single()
متد Single() برای زمانی استفاده میشود که انتظار دارید فقط یک رکورد مطابق با شرط وجود داشته باشد. اگر بیش از یک رکورد مطابق باشد یا هیچ رکوردی یافت نشود، یک استثنا رخ میدهد.
ویژگیها:
- تنها یک رکورد مطابق با شرط را بازمیگرداند.
- اگر هیچ رکوردی وجود نداشته باشد یا بیش از یک رکورد مطابق باشد، استثنای
InvalidOperationExceptionرخ میدهد. - مناسب برای مواقعی که باید دقیقاً یک رکورد وجود داشته باشد (مثلاً جستجوی براساس کلید اصلی یا شرایطی که یکتا هستند).
مثال:
var customer = context.Customers.Single(c => c.CustomerId == 123);
در این مثال، اگر چندین مشتری با این شناسه (که نباید ممکن باشد) یا هیچ مشتری وجود نداشته باشد، یک استثنا رخ میدهد.
4. SingleOrDefault()
متد SingleOrDefault() مشابه Single() است، اما اگر هیچ رکوردی پیدا نشود، مقدار پیشفرض (مانند null) بازگردانده میشود. اگر بیش از یک رکورد مطابق باشد، همچنان استثنا رخ میدهد.
ویژگیها:
- تنها یک رکورد مطابق با شرط را بازمیگرداند.
- اگر هیچ رکوردی وجود نداشته باشد، مقدار پیشفرض بازمیگردد.
- اگر بیش از یک رکورد یافت شود، استثنای
InvalidOperationExceptionرخ میدهد. - مناسب برای مواردی که احتمال میدهید هیچ رکوردی وجود نداشته باشد اما اگر بیش از یک رکورد یافت شود، خطا است.
مثال:
var customer = context.Customers.SingleOrDefault(c => c.CustomerId == 123);
در این مثال، اگر هیچ مشتری با شناسه 123 وجود نداشته باشد، null بازمیگردد. اگر بیش از یک مشتری با این شناسه وجود داشته باشد، استثنا رخ میدهد.
خلاصه تفاوتها:
| متد | رفتار اگر هیچ رکوردی پیدا نشود | رفتار اگر بیش از یک رکورد وجود داشته باشد | مناسب برای |
|---|---|---|---|
First() | ایجاد استثنای InvalidOperationException | فقط اولین رکورد را بازمیگرداند | زمانی که حداقل یک رکورد وجود دارد |
FirstOrDefault() | بازگرداندن مقدار پیشفرض (مثلاً null) | فقط اولین رکورد را بازمیگرداند | زمانی که ممکن است هیچ رکوردی وجود نداشته باشد |
Single() | ایجاد استثنای InvalidOperationException | ایجاد استثنای InvalidOperationException | زمانی که انتظار میرود دقیقاً یک رکورد وجود داشته باشد |
SingleOrDefault() | بازگرداندن مقدار پیشفرض (مثلاً null) | ایجاد استثنای InvalidOperationException | زمانی که ممکن است هیچ رکوردی وجود نداشته باشد ولی باید دقیقاً یک رکورد موجود باشد |
نکات مهم:
- از
First()وFirstOrDefault()زمانی استفاده کنید که ممکن است چندین رکورد مطابق با شرط وجود داشته باشد، اما تنها اولین رکورد برای شما مهم است. - از
Single()وSingleOrDefault()زمانی استفاده کنید که اطمینان دارید (یا انتظار دارید) فقط یک رکورد مطابق شرط وجود داشته باشد و اگر بیش از یک رکورد وجود داشته باشد، یک خطا در منطق شما است.
فرق IEnumerable و IQueryable در Entity Framework (EF)
در Entity Framework (EF)، دو اینترفیس IEnumerable<T> و IQueryable<T> برای کار با دادهها استفاده میشوند، اما تفاوتهای مهمی در نحوه پردازش کوئریها، اجرا و بهینهسازی آنها وجود دارد. این تفاوتها به طور مستقیم بر عملکرد برنامه تأثیر میگذارند، بهویژه در پروژههایی که با حجم بالای داده کار میکنند. بیایید این تفاوتها را به تفصیل بررسی کنیم:
1. IEnumerable<T>
IEnumerable<T> یک اینترفیس برای کار با مجموعههایی از دادهها در حافظه است. زمانی که از IEnumerable استفاده میکنید، کوئری بهطور کامل در سمت کلاینت اجرا میشود و دادهها از پایگاه داده واکشی شده و سپس فیلترها و سایر عملیات در حافظه اعمال میشوند.
ویژگیها:
- اجرای کوئری در حافظه: زمانی که دادهها واکشی میشوند، همه دادهها ابتدا از پایگاه داده به حافظه بارگذاری شده و سپس پردازش میشوند.
- مناسب برای کوئریهای در حافظه: اگر دادهها در حافظه باشند یا نیاز به اعمال پردازش پس از واکشی در حافظه دارید، از
IEnumerableاستفاده کنید. - اجرای فوری (Eager Execution): به محض اینکه کوئری نوشته شود و به یک
List<T>یا دیگر مجموعههای مشابه تبدیل شود (مثلاً با استفاده ازToList())، کوئری اجرا میشود.
نقاط قوت:
- مناسب برای زمانی که دادهها از قبل در حافظه هستند و دیگر نیازی به پایگاه داده نیست.
- برای پردازشهای بعد از واکشی دادهها (مثلاً فیلتر کردن و مرتبسازی دادهها در کد) میتواند مفید باشد.
نقاط ضعف:
- کارایی پایین برای کوئریهای پیچیده: از آنجا که کل دادهها ابتدا بارگذاری میشوند و سپس فیلتر میشوند، ممکن است کارایی در پروژههای بزرگ یا با حجم بالای داده کاهش یابد.
مثال:
IEnumerable<Customer> customers = context.Customers.ToList();
var filteredCustomers = customers.Where(c => c.City == "New York");در اینجا، کل لیست مشتریان ابتدا از پایگاه داده به حافظه بارگذاری شده و سپس فیلتر روی دادهها در حافظه اعمال میشود.
2. IQueryable<T>
IQueryable<T> برای کوئریهای LINQ to SQL طراحی شده و به EF اجازه میدهد تا کوئریها را به صورت تأخیری (Lazy Execution) به پایگاه داده ارسال کند. کوئریهای ساخته شده از طریق IQueryable تا زمانی که نتیجه نهایی درخواست نشود (مثلاً با فراخوانی ToList())، اجرا نمیشوند. همچنین کوئریها بهینهتر به SQL ترجمه میشوند و در پایگاه داده اجرا میشوند.
ویژگیها:
- اجرای کوئری در پایگاه داده: عملیات فیلتر، مرتبسازی و غیره در سطح پایگاه داده اعمال میشوند و تنها نتایج مورد نیاز به حافظه بازگردانده میشوند.
- مناسب برای کوئریهای سمت سرور: از
IQueryableزمانی استفاده میشود که بخواهید فیلترها و سایر عملیات مستقیماً در پایگاه داده اجرا شوند. - اجرای تأخیری (Lazy Execution): کوئری فقط زمانی اجرا میشود که نتیجه درخواست شود (مثلاً با استفاده از
ToList()یاFirst()). - ترجمه مستقیم به SQL: کوئریهای LINQ بهینه شده و به دستورات SQL تبدیل میشوند، بنابراین عملیات در سطح پایگاه داده سریعتر و کارآمدتر انجام میشود.
نقاط قوت:
- مناسب برای کار با مجموعههای بزرگ از دادهها، زیرا کوئریها در پایگاه داده فیلتر شده و فقط دادههای مورد نیاز به کلاینت ارسال میشوند.
- کارایی بهتر در مقایسه با
IEnumerable، زیرا کوئریها بهینه شده و در پایگاه داده اجرا میشوند.
نقاط ضعف:
- اگر دادهها به حافظه بارگذاری شده باشند و نیاز به پردازش در حافظه باشد،
IQueryableممکن است کاربرد کمتری داشته باشد.
مثال:
IQueryable<Customer> customers = context.Customers;
var filteredCustomers = customers.Where(c => c.City == "New York").ToList();در اینجا، کوئری LINQ به SQL تبدیل شده و تنها مشتریانی که در “New York” هستند از پایگاه داده واکشی میشوند.
تفاوتهای کلیدی بین IEnumerable و IQueryable:
| ویژگی | IEnumerable<T> | IQueryable<T> |
|---|---|---|
| محل اجرای کوئری | در حافظه کلاینت | در پایگاه داده |
| زمان اجرای کوئری | اجرای فوری (پس از نوشتن کوئری و درخواست داده) | اجرای تأخیری (تا زمانی که داده درخواست نشود) |
| ترجمه به SQL | کوئریها به SQL ترجمه نمیشوند | کوئریها به SQL ترجمه میشوند |
| کارایی برای دادههای بزرگ | ممکن است ضعیف باشد، زیرا کل دادهها به حافظه بارگذاری میشوند | کارایی بالاتر، زیرا فقط دادههای مورد نیاز واکشی میشوند |
| مناسب برای | عملیاتهای پردازشی در حافظه | کوئریهای پیچیده در پایگاه داده |
خلاصه استفاده از IEnumerable و IQueryable:
IQueryableمناسب برای کار با دادههای حجیم است، زیرا امکان بهینهسازی کوئریها در پایگاه داده را فراهم میکند. وقتی میخواهید دادهها را فیلتر کنید یا عملیات پیچیدهای انجام دهید که باید در پایگاه داده اجرا شود، ازIQueryableاستفاده کنید.IEnumerableبرای زمانی مناسب است که دادهها از قبل در حافظه هستند یا قصد دارید بعد از بارگذاری دادهها، عملیات خاصی را در حافظه انجام دهید. همچنین برای دادههای کوچک یا ساده که نیازی به کوئریهای پیچیده ندارند، میتوان از آن استفاده کرد.
فرق HttpPut با HttpPatch در Asp.Net Core
در ASP.NET Core، هر دو متد HTTP HttpPut و HttpPatch برای بهروزرسانی دادههای موجود در یک سرور استفاده میشوند، اما نحوه استفاده و عملکرد آنها در بهروزرسانی دادهها متفاوت است. بیایید تفاوتهای اصلی بین این دو متد را بررسی کنیم:
1. HttpPut
- روش بهروزرسانی کامل (Full Update):
PUTبرای بهروزرسانی کامل یک منبع (Resource) استفاده میشود. وقتی ازPUTاستفاده میکنید، باید تمام دادههای منبع را در درخواست ارسال کنید. این بدان معناست که درخواست باید تمام فیلدهای موجودیت را شامل شود، حتی اگر فقط برخی از آنها تغییر کرده باشند. - عملیات “جایگزین کردن” (Replace): درخواست
PUTکل منبع موجود را با دادههای جدید جایگزین میکند. اگر برخی فیلدها در درخواست ذکر نشده باشند، آنها در منبع حذف میشوند. بنابراین، همه فیلدها باید بهروز شده یا دوباره ارسال شوند. - ایجاد یا بهروزرسانی (Create or Update): از لحاظ استاندارد HTTP،
PUTمیتواند برای ایجاد یک منبع جدید نیز استفاده شود اگر منبع وجود نداشته باشد. با این حال، در بسیاری از APIها،POSTبرای ایجاد وPUTفقط برای بهروزرسانی استفاده میشود.
ویژگیهای کلیدی PUT:
- برای بهروزرسانی کامل منبع.
- در صورتی که فیلدی در درخواست وجود نداشته باشد، آن فیلد حذف میشود.
- میتواند برای ایجاد یک منبع جدید هم استفاده شود (در برخی پیادهسازیها).
مثال استفاده از PUT:
httpPUT /api/customers/1
Content-Type: application/json
{
"id": 1,
"name": "John Doe",
"email": "john@example.com",
"address": "123 Main St"
}در این مثال، تمامی فیلدهای مشتری با id 1 باید در درخواست PUT ارسال شوند، حتی اگر فقط فیلد email تغییر کرده باشد.
2. HttpPatch
- روش بهروزرسانی جزئی (Partial Update):
PATCHبرای بهروزرسانی جزئی یک منبع استفاده میشود. با استفاده ازPATCH، فقط فیلدهایی که تغییر کردهاند در درخواست ارسال میشوند و سایر فیلدها دست نخورده باقی میمانند. این روش برای زمانی مناسب است که تنها بخشی از منبع نیاز به بهروزرسانی دارد. - عملیات تغییر جزئی (Modify): درخواست
PATCHتنها فیلدهای مشخص شده در درخواست را تغییر میدهد و باقی فیلدهای منبع به همان حالت باقی میمانند.
ویژگیهای کلیدی PATCH:
- برای بهروزرسانی جزئی منبع.
- فقط فیلدهایی که تغییر میکنند، ارسال میشوند.
- از لحاظ کارایی بهتر است چون فقط اطلاعات تغییر یافته ارسال میشود.
مثال استفاده از PATCH:
httpPATCH /api/customers/1
Content-Type: application/json
{
"email": "john.newemail@example.com"
}در این مثال، تنها فیلد email مشتری با id 1 بهروزرسانی میشود و سایر فیلدها مثل name و address تغییری نمیکنند.
تفاوتهای کلیدی بین PUT و PATCH:
| ویژگی | HttpPut | HttpPatch |
|---|---|---|
| نوع بهروزرسانی | بهروزرسانی کامل (Full Update) | بهروزرسانی جزئی (Partial Update) |
| تغییرات در فیلدها | تمام فیلدها باید در درخواست وجود داشته باشند | فقط فیلدهای تغییر یافته در درخواست قرار میگیرند |
| عملیات روی منبع | منبع موجود را با دادههای جدید جایگزین میکند | فیلدهای مشخصشده را بهروزرسانی میکند |
| کاربرد | معمولاً برای بهروزرسانی کامل یک منبع یا جایگزینی آن استفاده میشود | مناسب برای بهروزرسانی بخشی از منبع |
| کارایی | به دلیل ارسال تمام دادهها کارایی کمتری دارد | کارایی بالاتر به دلیل ارسال فقط فیلدهای تغییر یافته |
| ایجاد منبع | میتواند در برخی موارد برای ایجاد منبع جدید هم استفاده شود | معمولاً فقط برای بهروزرسانی استفاده میشود |
چه زمانی از PUT یا PATCH استفاده کنیم؟
- از
PUTزمانی استفاده کنید که میخواهید یک منبع را بهطور کامل بهروزرسانی یا جایگزین کنید و همه فیلدهای آن را ارائه دهید. - از
PATCHزمانی استفاده کنید که فقط بخشی از دادههای منبع نیاز به تغییر دارند و نمیخواهید فیلدهای دیگر را در درخواست ارسال کنید.
نتیجهگیری:
HttpPutبرای بهروزرسانی کامل منبع و جایگزینی تمام دادهها استفاده میشود و نیازمند ارسال همه فیلدهای منبع است.HttpPatchبرای بهروزرسانی جزئی منبع به کار میرود و تنها تغییرات لازم را به سرور ارسال میکند، که کارایی بالاتری دارد و در بهروزرسانیهای جزئی مناسبتر است.
دستور Left Join در Entity Framework (EF) در Asp.Net Core
برای استفاده از Left Join در Entity Framework (EF) در ASP.NET Core، میتوانید از LINQ برای انجام یک کوئری Left Join استفاده کنید. در LINQ مستقیماً چیزی به نام LeftJoin وجود ندارد، اما میتوان با استفاده از GroupJoin و DefaultIfEmpty یک Left Join را شبیهسازی کرد. این کوئری به شما اجازه میدهد تا تمامی رکوردهای جدول اول را (حتی آنهایی که در جدول دوم مطابقت ندارند) واکشی کنید.
بیایید یک مثال از این کوئری را ببینیم:
مثال از Left Join با LINQ در Entity Framework:
فرض کنید دو جدول داریم:
- Customers: که شامل اطلاعات مشتریان است.
- Orders: که شامل سفارشهای مشتریان است.
هدف این است که تمام مشتریان را به همراه سفارشهای آنها بازیابی کنیم و مشتریانی که سفارشی ندارند نیز در نتیجه بازگردانده شوند.
ساختار کلاسها:
public class Customer
{
public int CustomerId { get; set; }
public string Name { get; set; }
public ICollection<Order> Orders { get; set; }
}
public class Order
{
public int OrderId { get; set; }
public int CustomerId { get; set; }
public string ProductName { get; set; }
}کوئری Left Join با LINQ:
var result = from customer in _context.Customers
join order in _context.Orders
on customer.CustomerId equals order.CustomerId into customerOrders
from order in customerOrders.DefaultIfEmpty()
select new
{
CustomerName = customer.Name,
OrderId = order?.OrderId, // استفاده از null-conditional برای سفارشهای خالی
ProductName = order?.ProductName
};
foreach (var item in result)
{
Console.WriteLine($"Customer: {item.CustomerName}, OrderId: {item.OrderId}, Product: {item.ProductName}");
}توضیح کوئری:
join order in _context.Orders on customer.CustomerId equals order.CustomerId into customerOrders- این بخش یک join انجام میدهد و سفارشهای مربوط به هر مشتری را در
customerOrdersذخیره میکند.
from order in customerOrders.DefaultIfEmpty():- این بخش بهصورت Left Join عمل میکند، به این معنا که اگر مشتری هیچ سفارشی نداشته باشد، مقدار
orderبهnullتنظیم میشود.
- این بخش بهصورت Left Join عمل میکند، به این معنا که اگر مشتری هیچ سفارشی نداشته باشد، مقدار
- در قسمت select:
- از
?.برای مدیریت مواردی که سفارش وجود ندارد (برای جلوگیری از خطاهایnull reference) استفاده میکنیم.
- از
نکات کلیدی:
DefaultIfEmpty()باعث میشود که حتی اگر مشتری سفارشی نداشته باشد، آن مشتری همچنان در نتایج ظاهر شود.GroupJoinدر LINQ شبیه به Left Join در SQL عمل میکند و با استفاده ازDefaultIfEmptyمیتوانیم به رفتار Left Join دست پیدا کنیم.
ترجمه به SQL:
این کوئری LINQ به یک LEFT OUTER JOIN در SQL ترجمه میشود که معادل زیر است:
SELECT c.Name, o.OrderId, o.ProductName
FROM Customers c
LEFT JOIN Orders o
ON c.CustomerId = o.CustomerId;
خلاصه:
برای انجام Left Join در Entity Framework با استفاده از LINQ، از ترکیب GroupJoin و DefaultIfEmpty() استفاده میشود. این روش تمام رکوردهای جدول سمت چپ (در اینجا Customers) را به همراه رکوردهای مطابقت داده شده از جدول سمت راست (در اینجا Orders) برمیگرداند و در صورت نبودن داده در جدول سمت راست، null را برای آن مقدار برمیگرداند.
تفاوت virtual و Sealed و Abstract و Class در Asp.Net Core
در ASP.NET Core (و به طور کلی در زبان C#)، کلمات کلیدی virtual، sealed، abstract و class برای تعریف رفتارها و محدودیتهای مختلف در کلاسها و متدها استفاده میشوند. هر یک از این کلمات کلیدی کاربرد خاصی دارند که در شیگرایی و طراحی نرمافزار اهمیت زیادی دارد. در ادامه به بررسی هر یک از این کلمات کلیدی و تفاوتهای آنها میپردازیم:
1. کلمه کلیدی class
- تعریف کلاس:
classبرای تعریف یک کلاس معمولی در C# استفاده میشود. کلاس میتواند شامل اعضایی مانند متدها، خصوصیات (properties)، فیلدها و غیره باشد. - ویژگیها:
- یک کلاس معمولی میتواند نمونهسازی (instantiate) شود.
- کلاسهای عادی میتوانند به عنوان پایه (Base Class) برای کلاسهای دیگر استفاده شوند.
- مثال:
public class Person { public string Name { get; set; } public void SayHello() { Console.WriteLine("Hello!"); } }2. کلمه کلیدی abstract
- تعریف کلاس و متدهای انتزاعی:
abstractبرای تعریف یک کلاس یا متد انتزاعی استفاده میشود. کلاسهای انتزاعی نمیتوانند مستقیماً نمونهسازی شوند و باید توسط یک کلاس دیگر به ارث برده شوند. کلاس انتزاعی میتواند شامل متدهای انتزاعی (بدون پیادهسازی) و همچنین متدهای معمولی (با پیادهسازی) باشد. - ویژگیها:
- یک کلاس
abstractنمیتواند مستقیماً نمونهسازی شود (یعنی نمیتوان از آن یک شیء ساخت). - اگر کلاس شامل یک متد
abstractباشد، آن متد باید در کلاس فرزند پیادهسازی (Override) شود. - کلاسهای
abstractبه عنوان کلاسهای پایه برای سایر کلاسها استفاده میشوند.
- یک کلاس
- مثال:
public abstract class Animal { public abstract void MakeSound(); // بدون پیادهسازی public void Sleep() // متد با پیادهسازی { Console.WriteLine("Sleeping..."); } } public class Dog : Animal { public override void MakeSound() { Console.WriteLine("Woof!"); } }- در این مثال، کلاس
Animalیک کلاس انتزاعی است و متدMakeSoundدر آن بدون پیادهسازی تعریف شده است. هر کلاسی که ازAnimalبه ارث ببرد (مثلDog) باید متدMakeSoundرا پیادهسازی کند.
3. کلمه کلیدی virtual
- تعریف متدهای قابل بازنویسی (Override): کلمه کلیدی
virtualبرای متدها، خصوصیات یا رویدادهایی استفاده میشود که قابل بازنویسی در کلاسهای فرزند باشند. یعنی یک متدvirtualبه کلاسهای فرزند این امکان را میدهد که پیادهسازی آن را تغییر دهند. - ویژگیها:
- متدهای
virtualدر کلاسهای پایه تعریف شده و قابل بازنویسی (Override) در کلاسهای مشتق شده هستند. - متدهای
virtualمیتوانند در کلاسهای مشتق شده تغییر داده شوند، اما در صورت عدم بازنویسی، پیادهسازی اولیه آنها استفاده میشود.
- متدهای
- مثال:
public class Bird { public virtual void Fly() { Console.WriteLine("Flying..."); } } public class Penguin : Bird { public override void Fly() { Console.WriteLine("Penguins cannot fly!"); } }- در این مثال، متد
Flyدر کلاسBirdبه صورتvirtualتعریف شده است، به این معنا که کلاسهای فرزند مثلPenguinمیتوانند پیادهسازی آن را تغییر دهند.
4. کلمه کلیدی sealed
- ممانعت از ارثبری بیشتر:
sealedبرای کلاسها و متدها استفاده میشود تا مانع از ارثبری یا بازنویسی بیشتر شود. به عبارت دیگر، وقتی یک کلاس به صورتsealedتعریف میشود، دیگر هیچ کلاسی نمیتواند از آن ارث ببرد. همچنین، وقتی یک متدsealedدر یک کلاس مشتق شده تعریف میشود، آن متد دیگر قابل بازنویسی در کلاسهای بعدی نیست. - ویژگیها:
- یک کلاس
sealedنمیتواند توسط کلاس دیگری به ارث برده شود. - یک متد
sealedنمیتواند در کلاسهای مشتق شده مجدداً بازنویسی شود.
- یک کلاس
- مثال:
public sealed class Car { public void Drive() { Console.WriteLine("Driving..."); } } // این کد خطا میدهد، زیرا نمیتوان از یک کلاس sealed ارث برد // public class SportsCar : Car { } public class Animal { public virtual void Eat() { Console.WriteLine("Eating..."); } } public class Dog : Animal { public sealed override void Eat() { Console.WriteLine("Dog is eating..."); } } // کلاسهای دیگر نمیتوانند متد Eat را دوباره بازنویسی کنند // public class Poodle : Dog // { // public override void Eat() { } // این کد خطا میدهد // }- در این مثال، کلاس
Carبه صورتsealedتعریف شده است، بنابراین نمیتوان از آن ارث برد. همچنین، متدEatدر کلاسDogبه صورتsealedبازنویسی شده است، بنابراین دیگر در کلاسهای فرزند (مثلPoodle) قابل بازنویسی نیست.
خلاصه تفاوتها:
| کلمه کلیدی | توضیح | ویژگی اصلی |
|---|---|---|
class | تعریف یک کلاس معمولی که میتواند نمونهسازی شود. | کلاسهای معمولی بدون محدودیت خاص. |
abstract | تعریف یک کلاس یا متد انتزاعی که نمیتوان از آن نمونهسازی کرد و باید توسط کلاسهای فرزند پیادهسازی شود. | به عنوان پایه برای سایر کلاسها؛ متدهای انتزاعی باید در کلاسهای فرزند پیادهسازی شوند. |
virtual | تعریف متدی که در کلاسهای مشتق شده قابل بازنویسی است. | متدهای virtual در کلاسهای فرزند بازنویسی میشوند. |
sealed | ممانعت از ارثبری بیشتر از یک کلاس یا بازنویسی بیشتر یک متد. | کلاسهای sealed نمیتوانند به ارث برده شوند و متدهای sealed دیگر قابل بازنویسی نیستند. |
نتیجهگیری:
classیک کلاس معمولی است که میتواند نمونهسازی شود.abstractبرای کلاسها و متدهایی است که نمیتوانند مستقیماً استفاده شوند و باید در کلاسهای مشتق شده پیادهسازی شوند.virtualبه شما اجازه میدهد متدهایی تعریف کنید که در کلاسهای فرزند قابل بازنویسی باشند.sealedبرای جلوگیری از ارثبری یا بازنویسی بیشتر استفاده میشود.
خطای Cross-Origin Request Blocked چیست و چگونه بر طرف میشود
خطای Cross-Origin Request Blocked (مسدود شدن درخواست بین مبدأها) زمانی رخ میدهد که یک برنامه وب سعی میکند از یک دامنه (Origin) به یک منبع از دامنه دیگری درخواست HTTP ارسال کند، اما مرورگر به دلیل سیاستهای CORS (Cross-Origin Resource Sharing) این درخواست را مسدود میکند. CORS یک مکانیزم امنیتی است که مرورگرها برای محافظت از کاربران در برابر حملات Cross-Site Request Forgery (CSRF) و Cross-Site Scripting (XSS) به کار میگیرند.
دلایل رخ دادن خطای CORS:
- دامنه، پورت یا پروتکل مبدأ درخواست با منبعی که درخواست به آن ارسال شده است متفاوت است. به عنوان مثال، اگر صفحهای از
http://example.comبخواهد اطلاعاتی ازhttp://anotherdomain.comدریافت کند، CORS باید اجازه این درخواست را بدهد. - سرور مقصد (API یا سرور دیگر) پیکربندی نشده است تا درخواستهای از دامنههای خارجی را بپذیرد.
چگونه مشکل CORS را برطرف کنیم؟
برای رفع این مشکل، باید به سرور مقصد اطلاع دهید که اجازه میدهد درخواستهایی از سایر مبدأها (Origins) به آن ارسال شود. این کار با استفاده از پیکربندی CORS انجام میشود.
راهحلهای معمول برای رفع خطای CORS:
1. تنظیمات CORS در سرور
در سمت سرور، باید CORS را به درستی پیکربندی کنید تا درخواستهای از دامنههای دیگر را بپذیرد. در ادامه نحوه پیکربندی CORS در برخی از فناوریهای سرور محبوب آورده شده است:
ASP.NET Core:
در ASP.NET Core، شما میتوانید CORS را با استفاده از Middleware تنظیم کنید. به عنوان مثال، برای اجازه دادن به همه دامنهها:
مراحل تنظیم CORS در ASP.NET Core:
- در فایل
Startup.csیاProgram.cs، سرویس CORS را به پروژه اضافه کنید:
public void ConfigureServices(IServiceCollection services)
{
services.AddCors(options =>
{
options.AddPolicy("AllowAllOrigins",
builder => builder.AllowAnyOrigin()
.AllowAnyMethod()
.AllowAnyHeader());
});
services.AddControllers(); // یا هر سرویس دیگری که نیاز دارید
}
- سپس در متد
Configureاین سیاست را اعمال کنید:
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
app.UseCors("AllowAllOrigins"); // اعمال سیاست CORS
app.UseRouting();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}با این کار، تمام درخواستهای CORS از هر مبدأ، برای همه متدها و هدرها پذیرفته میشود.
Node.js با استفاده از Express:
برای فعال کردن CORS در Node.js با استفاده از Express، میتوانید از بسته cors استفاده کنید:
- ابتدا بسته
corsرا نصب کنید:npm install cors - سپس آن را به پروژه خود اضافه کنید:
const express = require('express'); const cors = require('cors'); const app = express(); // اجازه به تمام دامنهها app.use(cors()); app.get('/api/data', (req, res) => { res.json({ message: 'This is CORS enabled.' }); }); app.listen(3000, () => { console.log('Server is running on port 3000'); });این کد اجازه میدهد که هر دامنهای بتواند درخواستهای CORS را به سرور ارسال کند.
2. تنظیمات در کلاینت (Front-End)
در مواردی که شما نمیتوانید سرور مقصد را تغییر دهید، ممکن است بتوانید به صورت موقت مشکل را در سمت کلاینت برطرف کنید. برخی از راهحلهای موقتی عبارتند از:
- استفاده از پروکسی (Proxy): میتوانید درخواستها را به یک پروکسی ارسال کنید که از سمت سرور مقصد CORS را پشتیبانی میکند. به عنوان مثال، در یک برنامه Angular میتوانید از یک پروکسی داخلی برای ارسال درخواستهای API استفاده کنید.برای Angular، در فایل
proxy.conf.jsonمیتوانید تنظیمات زیر را اضافه کنید:
{ "/api": { "target": "http://your-api-server.com", "secure": false, "changeOrigin": true } }سپس در angular.json این فایل پروکسی را به serve اضافه کنید:
"serve": {
"options": {
"proxyConfig": "src/proxy.conf.json"
}
}
- تنظیمات مرورگر: در زمان توسعه، میتوانید به صورت موقت CORS را در مرورگر غیرفعال کنید. اما این روش برای محیط تولید توصیه نمیشود و فقط در زمان دیباگ و توسعه باید استفاده شود.
3. Preflight Request (پیشپردازش CORS)
هنگامی که درخواستهایی مانند POST, PUT, DELETE یا درخواستهایی با هدرهای خاص ارسال میشوند، مرورگر ابتدا یک Preflight Request از نوع OPTIONS به سرور ارسال میکند. سرور باید در پاسخ به این درخواست، هدرهای CORS را ارسال کند تا مرورگر درخواست اصلی را ارسال کند.
هدرهایی که سرور باید در پاسخ ارسال کند شامل موارد زیر هستند:
Access-Control-Allow-Origin: دامنهای که اجازه ارسال درخواست به سرور را دارد (یا*برای اجازه به همه دامنهها).Access-Control-Allow-Methods: لیستی از متدهای HTTP مجاز (مانند GET, POST, PUT, DELETE).Access-Control-Allow-Headers: لیستی از هدرهایی که میتوانند در درخواست استفاده شوند (مانند Content-Type, Authorization).
مثال از پاسخ صحیح سرور:
HTTP/1.1 200 OK
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, PUT, DELETE
Access-Control-Allow-Headers: Content-Typeنتیجهگیری:
برای رفع خطای Cross-Origin Request Blocked، باید اطمینان حاصل کنید که سرور مقصد به درستی پیکربندی شده است تا درخواستهای بین مبدأیی (CORS) را مجاز کند. این کار معمولاً با پیکربندی مناسب در سمت سرور و پاسخ به درخواستهای OPTIONS (Preflight) انجام میشود.
آموزش نصب و تنظیم Nginx در لینوکس
وب سرور Nginx با ویژگیهای منحصر به فرد خود، کاربردهای گستردهای در زمینه های مختلف دارد. یکی از کاربردهای اصلی آن، میزبانی وبسایت های پربازدید است. Nginx می تواند ترافیک سنگین را به راحتی مدیریت کند و سرعت لود صفحات را افزایش دهد. در زمینه استریم ویدیویی و پخش محتوا، Nginx یک ابزار قدرتمند محسوب می شود. با قابلیت کش کردن محتوا و تحویل سریع ویدیو، Nginx می تواند تجربه کاربری بهتری را برای مشاهده محتوای ویدیویی فراهم کند. با توجه به انعطاف پذیری و کارایی بالای Nginx، این وب سرور در زمینههای متنوعی از جمله وبسایتها، سرویسهای ابری، پلتفرمهای استریم کاربرد گستردهای دارد.
وب سرور Nginx چیست؟

در دنیای پرچالش وب امروز، یکی از مهمترین نیازها، مدیریت موثر ترافیک وبسایتها و برنامههای مبتنی بر وب است. در این میان، وب سرور Nginx با ویژگیهای منحصر به فرد خود، به یک گزینه محبوب و پرکاربرد تبدیل شده است. Nginx یک نرمافزار منبع باز (Open Source) و رایگان است که در سال 2004 توسط ایگور سیسوف، یک برنامهنویس روسی توسعه یافت. هدف اصلی آن، ایجاد یک وب سرور سبک، سریع و کارآمد بود که بتواند با ترافیک سنگین به خوبی کنار بیاید. یکی از ویژگی های برجسته Nginx، معماری رویداد محور و غیرمتمرکز آن است. این معماری باعث می شود که Nginx بتواند با مصرف منابع بسیار کمتر، ترافیک بیشتری را پردازش کند. در نتیجه، هزینههای میزبانی کاهش و کارایی سیستم افزایش مییابد. Nginx از امنیت قابل توجهی نیز برخوردار است. این وب سرور قادر است از وبسایتها در برابر حملات متداول مانند حملات DDOS محافظت کند و همچنین میتواند ترافیک را رمزنگاری کند تا امنیت دادهها افزایش یابد. کاربرد گسترده Nginx در زمینههای مختلف از جمله میزبانی وبسایتهای پربازدید، پلتفرم های استریم ویدیویی، سرویسهای ابری و معماریهای میکروسرویس، نشان دهنده قدرت و کارایی این وب سرور است. شرکت های بزرگی مانند Netflix ،Cloudflare و بسیاری دیگر، از Nginx برای ارائه خدمات وب خود استفاده میکنند. Nginx با ترکیبی از سرعت، کارایی، امنیت و انعطاف پذیری، به یکی از پرکاربردترین و محبوبترین وب سرورهای دنیای امروز تبدیل شده است. این ابزار قدرتمند، راه را برای مدیریت موثر ترافیک وب و ارائه تجربه کاربری بهتر هموار میکند.
مزایا و معایب استفاده از Nginx
Nginx با مزایای قابل توجهی مانند کارایی بالا، امنیت و انعطافپذیری همراه است. این ویژگیها آن را به یک گزینه محبوب برای میزبانی وبسایتها، برنامههای وب و سرویسهای مختلف تبدیل کرده است. با این حال، معایبی نیز دارد که باید در نظر گرفته شوند. برخی از مزایای استفاده از Nginx عبارتند از:
- کارایی و عملکرد بالا: Nginx با معماری رویداد محور (Event-driven architecture) و غیرمتمرکز خود، قادر است ترافیک سنگین را با مصرف منابع بسیار کم مدیریت کند. این امر باعث کاهش هزینههای میزبانی و افزایش سرعت لود صفحات میشود.
- امنیت بالا: Nginx از امنیت قابل توجهی برخوردار است و میتواند از وب سایتها در برابر حملات متداول مانند حملات DDOS محافظت کند. همچنین، قابلیت رمزگذاری ترافیک را نیز دارد تا دادهها به صورت امن انتقال یابند.
- پشتیبانی از پروتکلهای مختلف: Nginx میتواند از پروتکلهای متنوعی مانند HTTP، HTTPS، SMTP، POP3 و IMAP پشتیبانی کند. این ویژگی آن را به یک گزینه ایدهآل برای میزبانی انواع سرویسهای وب تبدیل میکند.
- جامعه فعال و پشتیبانی خوب: Nginx دارای یک جامعه فعال و پشتیبانی خوب است. این امر به معنای دسترسی به منابع، راهنماها و بهروزرسانیهای منظم است که میتواند استفاده از این وب سرور را آسانتر کند.
برخی از معایب استفاده از Nginx عبارتند از:
- پیچیدگی تنظیمات: Nginx دارای یک ساختار پیچیده است و تنظیمات آن میتواند برای کاربران مبتدی سخت و چالش برانگیز باشد. به همین دلیل کار کردن با آن ممکن است نیاز به یادگیری و تمرین زیاد داشته باشد.
- محدودیتهای ذاتی: Nginx برای پردازش برخی از زبانهای برنامهنویسی مانند PHP و Python محدودیتهایی دارد. این امر ممکن است در برخی موارد، استفاده از وب سرورهای دیگر را ضروری کند.
- مدیریت پیچیده: در محیطهای بزرگ با تعداد زیادی سرور، مدیریت و نگهداری Nginx میتواند پیچیده شود و نیاز به ابزارها و فرایندهای خاصی داشته باشد.
نصب Nginx
قبل از شروع نصب، بهتر است مخازن نرمافزاری (Software Repository) سیستم خود را بروزرسانی کنید. این کار را میتوانید با دستور زیر انجام دهید:
sudo apt update
پس از بروزرسانی مخازن نرمافزاری، میتوانید Nginx را با دستور زیر نصب کنید:
sudo apt install nginx
این دستور، آخرین نسخه پایدار Nginx را از مخازن اوبونتو دریافت و نصب خواهد کرد.
پس از نصب موفق، وب سرور Nginx به صورت خودکار راهاندازی میشود. کاربران میتوانند با دستور زیر از وضعیت آن اطلاع یابند:
sudo systemctl status nginx
این دستور، وضعیت فعلی سرویس Nginx را نمایش میدهد.
همچنین کاربران با استفاده از دستور زیر می توانند نسخه نصب شده NGINX را بررسی کنند:
nginx -v
پیکربندی فایروال
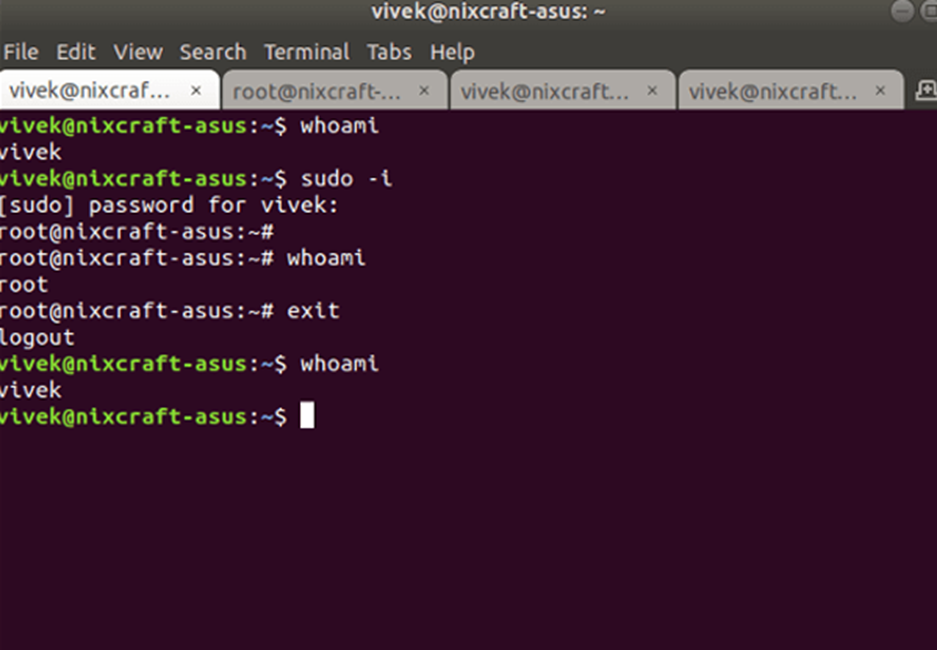
پس از نصب موفق Nginx در سیستم عامل اوبونتو، یکی از مراحل مهم و ضروری، تنظیم صحیح فایروال است. فایروال نقش حیاتی در محافظت از وب سرور شما در برابر تهدیدات امنیتی و حملات احتمالی دارد. اولین قدم در پیکربندی فایروال، نصب فایروال UFW است. این فایروال به صورت پیشفرض در اوبونتو نصب نشده است، بنابراین باید آن را با دستور زیر نصب کنید:
sudo apt-get install ufw
پس از نصب UFW، باید به عبور ترافیک HTTP (پورت 80) و HTTPS (پورت 443) از فایروال اجازه دهید. این کار را میتوانید با دستو زیر انجام دهید:
sudo ufw allow Nginx ‘HTTP’
sudo ufw allow ‘Nginx HTTPS’
sudo ufw allow ‘Nginx Full’
این دستورات، قواعد جدیدی در فایروال ایجاد میکنند که به Nginx اجازه میدهند تا از پورتهای 80 و 443 ترافیک را دریافت کند. پس از وارد کردن دستورات بالا، باید سرویس Nginx را با استفاده از دستور زیر راهاندازی کنیم:
sudo systemctl start nginx
کاربران ممکن است بخواهند تا سرویس Nginx در هنگام بوت شدن سیستم به طور خودکار راهاندازی شود، این ویژگی را با استفاده از دستور زیر میتوانند فعال کنند:
sudo systemctl enable nginx
پس از تنظیم قوانین مورد نیاز، شما میتوانید فایروال UFW را با دستور زیر فعال کنید:
sudo ufw enable
این دستور، فایروال را فعال کرده و تنها به ترافیک مجاز اجازه عبور میدهد.
جهت اطمینان از تنظیم صحیح فایروال، میتوانید وضعیت آن را با دستور زیر بررسی کنید:
sudo ufw status
این دستور، لیستی از قواعد فعال در فایروال را نمایش میدهد.
بررسی وضعیت Nginx
پس از نصب Nginx در سیستم عامل اوبونتو، باید بتوانید وضعیت آن را بررسی و کنترل کنید. این امر به شما این امکان را میدهد تا از عملکرد صحیح وب سرور خود اطمینان حاصل کنید، مشکلات احتمالی را شناسایی کرده و اقدامات لازم را برای رفع آنها انجام دهید. یکی از روشهای ساده برای بررسی وضعیت Nginx، استفاده از دستور systemctl است. با استفاده از دستور زیر میتوانید ببینید که آیا سرویس Nginx در حال اجرا است یا خیر:
sudo systemctl status nginx
لاگهای Nginx میتوانند اطلاعات ارزشمندی در مورد عملکرد وب سرور، خطاها و رفتار کاربران به شما ارائه دهند. لاگهای Nginx به طور پیشفرض در مسیرهای زیر قرار دارند:
Access Log: /var/log/nginx/access.log
Error Log: /var/log/nginx/error.log
میتوانید با دستورات زیر، محتویات این لاگها را مشاهده کنید:
sudo tail -n 20 /var/log/nginx/access.log
sudo tail -n 20 /var/log/nginx/error.log
این دستورات، ۲۰ خط آخر لاگها را نمایش میدهند تا بتوانید رفتار اخیر وب سرور را بررسی کنید.
مدیریت Nginx
برای بهرهگیری حداکثری از تواناییهای Nginx، نیاز به مدیریت صحیح و کنترل کامل بر آن دارید. مدیریت صحیح Nginx در اوبونتو، به شما این امکان را میدهد تا از تمام تواناییهای این وب سرور قدرتمند بهرهمند شوید. با داشتن کنترل کامل بر سرویس، فایلهای پیکربندی، ماژولها و ابزارهای مدیریت، میتوانید Nginx را برای نیازهای خاص خود تنظیم کرده و عملکرد آن را بهینه کنید. یکی از روشهای اصلی مدیریت Nginx در اوبونتو، استفاده از دستور systemctl است. این دستور به شما این اجازه را میدهد تا سرویس Nginx خود را راهاندازی، متوقف و یا راهاندازی مجدد کنید. برای مثال:
- راهاندازی : sudo systemctl start nginx
- توقف : sudo systemctl stop nginx
- راهاندازی مجدد : sudo systemctl restart nginx
- بررسی وضعیت : sudo systemctl status nginx
تفاوت Stored Procedure و Function در SQL Server
Stored Procedure های اشیایی هستند که در اولین بار کامپایل شده و فرمت آن ذخیره می شود (کد کامپایل شده) و در دفعات بعدی میتوان آن را فراخوانی کرد و این مورد خود باعث افزایش سرعت اجرای آن می شود . اما Function ها در هر بار فراخوانی آنها ، ابتدا می بایست کامپایل شوند و سپس اجرا میشوند .
تفاوت های پایه:
Function ها حتما باید مقداری را به عنوان خروجی برگردانند در صورتی که در Stored Procedure ها اختیاری می باشدProcedure می تواند صفر یا n مقدار برگرداند.
Function های فقط می توانند پارامترهای ورودی داشته باشند در صورتی که Stored Procedure ها می توانند پارامتر های Input و Output داشته باشند .
Function ها میتوانند از داخل یک Stored Procedure فراخوانی شوند در حالی که نمیتوان در داخل یک Function اقدام به فراخوانی یک Procedure کرد .
تفاوت های پیشرفته :
Stored Procedure ها اجازه استفاده از دستور SELECT را به خوبی می دهند و همچنین دستورات (DML) insert,update,delete در حالیکه Function ها فقط اجازه استفاده از دستور SELECT را دارند .
Stored Procedure ها نمی توانند در داخل دستورات SELECT استفاده شوند درحالیکه Function می تواند در داخل دستورات SELECT جاسازی شود .
Stored Procedure ها نمی توانند در هر جای دستورات SQL استفاده شوند ، برای نمونه نمی توانند در قسمت های WHERE/HAVING,SELECT استفاده شوند در حالیکه این محدودیت برای Function وجود ندارد .
می توان در داخل Stored Procedure ها استثنا ها را با استفاده از بلوک های try-catch مدیریت کرد در حالیکه در داخل Function نمی توان بلوک های try-catch را مورد استفاده قرار داد .
Function ها می توانند یک Table را در خروجی برگردانند که این Table میتواند در داخل دستورات Join با جداول دیگر مورد استفاده قرار گیرد .
مهمترین ویژگی Stored Procedure ها نسبت به Function ها نگهداری و قابلیت استفاده مجدد execution plan می باشد درحالیکه برای Function ها هربار کامپایل می شود .
نحوه ساخت Function در Sql Server :
-- ================================================
-- Template generated from Template Explorer using:
-- Create Scalar Function (New Menu).SQL
--
-- Use the Specify Values for Template Parameters
-- command (Ctrl-Shift-M) to fill in the parameter
-- values below.
--
-- This block of comments will not be included in
-- the definition of the function.
-- ================================================
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <Author,,Name>
-- Create date: <Create Date, ,>
-- Description: <Description, ,>
-- =============================================
CREATE FUNCTION <Scalar_Function_Name, sysname, FunctionName>
(
-- Add the parameters for the function here
<@Param1, sysname, @p1> <Data_Type_For_Param1, , int>
)
RETURNS <Function_Data_Type, ,int>
AS
BEGIN
-- Declare the return variable here
DECLARE <@ResultVar, sysname, @Result> <Function_Data_Type, ,int>
-- Add the T-SQL statements to compute the return value here
SELECT <@ResultVar, sysname, @Result> = <@Param1, sysname, @p1>
-- Return the result of the function
RETURN <@ResultVar, sysname, @Result>
END
GOمیتوان مطابق با شکل زیر نیز فانکشن را ایجاد نمود
نحوه ساخت Stored Procedure در Sql Server :
-- ================================================
-- Template generated from Template Explorer using:
-- Create Procedure (New Menu).SQL
--
-- Use the Specify Values for Template Parameters
-- command (Ctrl-Shift-M) to fill in the parameter
-- values below.
--
-- This block of comments will not be included in
-- the definition of the procedure.
-- ================================================
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <Author,,Name>
-- Create date: <Create Date,,>
-- Description: <Description,,>
-- =============================================
CREATE PROCEDURE <Procedure_Name, sysname, ProcedureName>
-- Add the parameters for the stored procedure here
<@Param1, sysname, @p1> <Datatype_For_Param1, , int> = <Default_Value_For_Param1, , 0>,
<@Param2, sysname, @p2> <Datatype_For_Param2, , int> = <Default_Value_For_Param2, , 0>
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
-- Insert statements for procedure here
SELECT <@Param1, sysname, @p1>, <@Param2, sysname, @p2>
END
GO
پارتیشن بندی (Partition) در Sql Server
یکی از قابلیت های بانک اطلاعاتی در SQL Server پارتیشن بندی می باشد. قابلیت پارتیشن بندی به SQL در سال 2005 اضافه گردید و در نسخه های بعدی که به کاربران معرفی گردید بهبود و گسترش یافت.
با استفاده از این قابلیت این امکان وجود دارد که جداولی که حجم داده هایش بسیار زیاد است به ساختارهای جداگانه تقسیم شود. به کد نویسی سمت Application به هیچ عنوان برای برای استفاده از قابلیت پارتیشن بندی SQL نیازی وجود ندارد.
ما در این مقاله پارتیشن بندی در SQL سرور را معرفی خواهیم کرد. شما در پایان این مقاله خواهید فهمید که چرا باید پارتیشن بندی را انجام دهیم و مراحل پارتیشن بندی در SQL سرور چگونه است.
پارتیشن بندی چیست ؟
پارتیشن بندی یک فرآیند برای پایگاه داده است که جداول بسیار بزرگ به چندین قسمت کوچکتر تقسیم می شوند. با تقسیم یک جدول بزرگ به جداول کوچکتر و جداگانه، قسمت هایی که فقط به بخشی از داده دسترسی دارند سپس سریعتر اجرا می شوند، زیرا داده های کمتری برای اسکن وجود دارد.
هدف اصلی از پارتیشن بندی کمک به حفظ جداول بزرگ و کاهش زمان پاسخ کلی برای خواندن و بارگذاری داده ها برای عملکردهای خاص SQL است.
چرا باید پایگاه داده را پارتیشن بندی کنیم ؟
با تقسیم بندی داده ها، می توان انبوهی از داده ها را به پارتیشن های كوچكتر و در نتیجه با مدیریت بهتر، می توان به مسائل مربوط به پشتیبانی از جداول بزرگ بهتر پاسخ داد. پارتیشن بندی داده ها همچنین منجر به بارگذاری سریعتر داده ها، نظارت آسان بر داده های قدیمی و بازیابی اطلاعات می شود.
پارتیشن بندی در SQL Server
SQL Server از پارتیشن بندی جدول و فهرست پشتیبانی می کند. داده های جداول و نمایه های تقسیم شده به واحدهایی تقسیم می شوند که به صورت اختیاری ممکن است در بیش از یک گروه در پایگاه داده پخش شوند. داده ها به صورت افقی تقسیم می شوند ، بنابراین گروه های ردیف به صورت جداگانه تقسیم می شوند
سطوح مختلف پارتیشن بندی
پارتیشن بندی در SQL شامل سه سطح می باشد. در سطح اول ما پارتیشن بندی را در سطح داده، سپس در تابع پارتیشن و در سطح سوم نیز در محل ذخیره سازی ما پارتیشن بندی را انجام می دهیم. ما در ادامه این سه سطح را به شما معرفی خواهیم کرد.
• سطح 1: داده؛ در سطح اول داده هایی که عمل پارتیشن بندی بر روی آنها رخ می دهد.
• سطح 2: Partition Function؛ در سطح دوم قسمتی است که پارتیشن بندی را مشخص می نماید و تابع پارتیشن، نام دارد..
• سطح 3: Partition Scheme: در سطح سوم محلی که ذخیره سازی پارتیشن ها را معلوم می کند.
مراحل پارتیشن بندی در SQL Server
مراحل پارتیشن بندی در SQL را می توان از دو دید مختلف مورد بررسی قرار داد. ما می توانیم مراحل پارتیشن بندی را از دیدDeveloper و مدیر بانک اطلاعاتی مورد بررسی قرار دهیم. ما در ادامه به تفصیل به بررسی هر کدام از مراحل پارتیشن بندی از نگاه پیاده ساز و Database Admin خواهیم پرداخت.
دیدگاه های مختلف پارتیشن بندی :
- از دید پیاده ساز
- از دید مدیر بانک اطلاعاتی
مراحل پارتیشن بندی در SQL Server از دید Developer
مراحل پارتیشن بندی از دیدگاه توسعه دهند دو مرحله را دارد. در مرحله اول باید شما کلید پارتیشن را مشخص کنیم. و در مرحله بعدی باید تعداد پارتیشن ها را تعیین کنید.
مرحله 1: مشخص کردن کلید پارتیشن با Partition Key
یکی از مهمترین بخش های پارتیشن بندی مشخص کردن Partition Key می باشد. در اینجا باید به عنوان کلید پارتیشن بندی شما فیلدی را انتخاب کنید. انتخاب شما باید بر اساس جستجوی بیشتر باشد.
برای مثال ما سیستم مالی را در آورده ایم. ایجاد سند یکی از فرم های بسیار مهم این بخش می باشد. در جدولی که مربوط به این فرم است، در جداول آیا انتخاب تاریخ می تواند گزینه مناسبی برای Partition Key در نظر گرفته شود؟
در این انتخاب نکته ی دیگری که باید شما در نظر بگیرید این است از اینجا به بعد برای داشتن بهترین کارایی، اگر تاریخ را به عنوان Partition Key انتخاب کرده اید، در تمام Query جستجو باید حتما تاریخ را داشته باشید.
بنابراین ممکن است که با یک سیاست خاص مجبور باشید متقاعد کنید کاربران سیستم را که در فرم های جستجو حتماً فیلد تاریخ را تنظیم نمایند.
مرحله 2: تعیین تعداد پارتیشن ها
باید یک تخمین درست با در نظر گرفتن حجم داده و میزان پیشرفت از تعداد پارتیشن های مورد نیاز داشته باشید. به عنوان مثال اگر تاریخ اساس کلید پارتیشن بندی شما است، بین ماه و سال باید شما انتخاب بعدی خود را داشته باشید؟ مثلاً اگر در یک ماه تعداد رکوردهای شما بالای 30.000.000 باشد، براساس ماه پارتیشن بندی گزینه بهتری می تواند باشد.
توجه داشته باشید: زمان جستجو نیز هر چه تعداد رکورد پارتیشن بیشتر باشد، بیشتر خواهد شد، حتما دقت داشته باشید که تعداد پارتیشن ها را به درستی انتخاب کرده اید.
مراحل پارتیشن بندی در SQL server از دید مدیر بانک اطلاعاتی
حالا که به خوبی کلید و تعداد پارتیشن ها را مشخص کردید نوبت به بررسی توسط مدیر بانک اطلاعاتی رسیده است. مراحل پارتیشن بندی در SQL از دید مدیر بانک اطلاعاتی شامل دو مرحله ایجاد Filegroup و Partition Function می باشد.
مرحله 1: ایجاد Filegroup
یک Filegroup را می توان به ازای هر پارتیشن ایجاد کرد. این امکان وجود دارد که چند پارتیشن و یا حتی تمام پارتیشن ها را در یک Filegroup قرار دهیم.
مرحله 2: مشخص کردن Partition function
محل قرار گیری رکوردها در SQL را می توان با استفاده از Partition Function مشخص کرد. آنها را می توان در یک Partition مشخص نمود. نقاط مرزی که برای تقسیم داده ها از طریق Partition Function مشخص می شود را نیز ایجاد کرد.
حالا که با مفهوم پارتیشن بندی، سطوح و مراحل آن آشنا شدیم در ادامه مقاله با آموزش دو مبحث کاربردی پارتیشن بندی در SQL با ما همراه بشید.
- ایجاد پارتیشن به صورت ویزاردی زمانی که پارتیش را بخواهیم روی کلید اصلی جدول ایجاد کنیم
در این قسمت می خواهیم عملیات پارتیشن بندی را به صورت ویزادی بر روی فیلد کلاستر جدول tblNew انجام دهیم.
لازم به ذکر است که چهار فایل گروپ به این دیتابیس به نام های FG1,FG2,FG3,FG4 اضافه کنید.
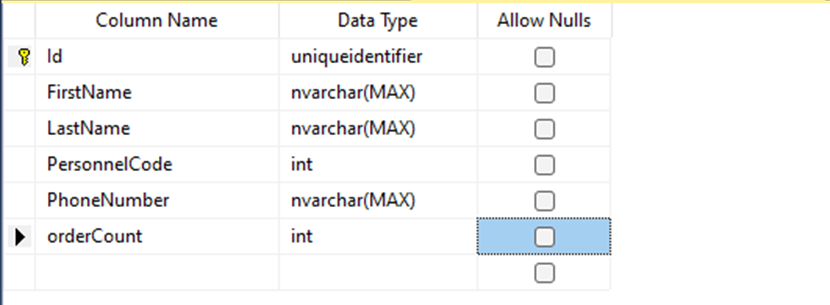
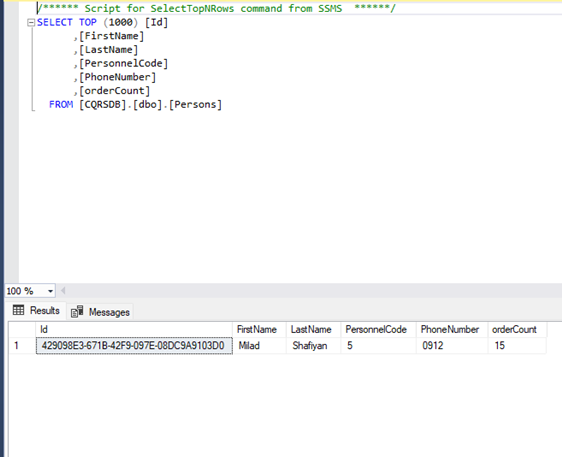
- در این مرحله Filegroup های مورد نظر (چهار Filegroup) را ایجاد می کنیم.
- در این مرحله بر روی جدولی که می خواهیم پارتیشن شود، کلیک راست کرده و گزینه Storage و سپس گزینه Create Partition را کلیک می کنیم.
- در این مرحله پنجره خوش آمد گویی نمایان می شود.
- در این مرحله مشخص می کنیم که بر روی کدام ستون می خواهیم عمل پارتیشن صورت پذیرد (نام ستون پارتیشن را وارد می کنیم).
- در این مرحله نام پارتیشن فانکشن مورد نظرمان را وارد می کنیم.
- در این مرحله نام Partition Scheme خود را می دهیم.
- حال در اینجا :
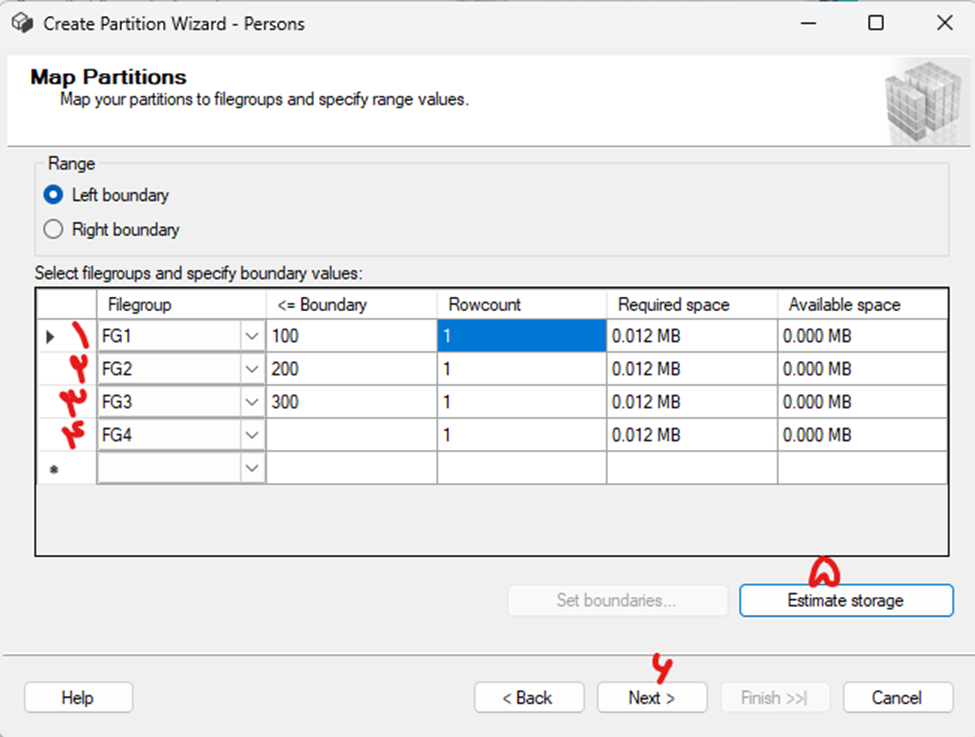
- در این مرحله یا می توانیم اسکریپت بگریم (Create Script) و یا اینکه بلافاصله اقدام به ایجاد پارتیشن کنیمRun Immediately و یا اینکه به صورت یک فایل آن اسکریپ را ذخیره نماییم(Save Script) و یا اینکه در اسکریپت را در حافظه ذخیره کنیم(Script to Clipboard).
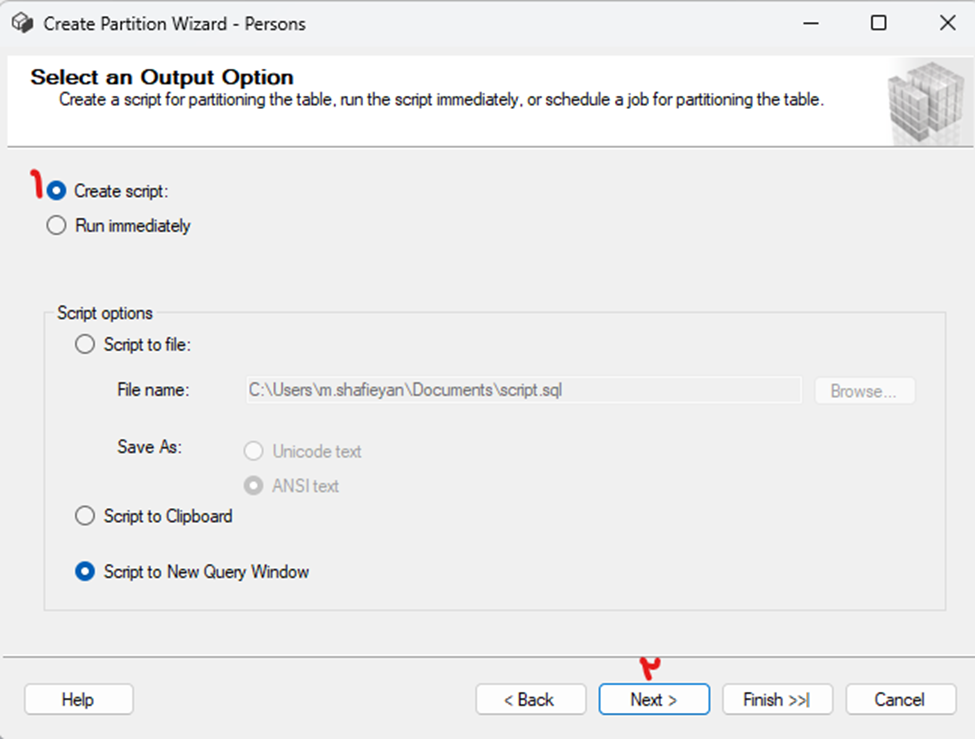
- خلاصه ای از تنظیماتی که انجام داده ایم در این پنجره نمایش داده می شود.
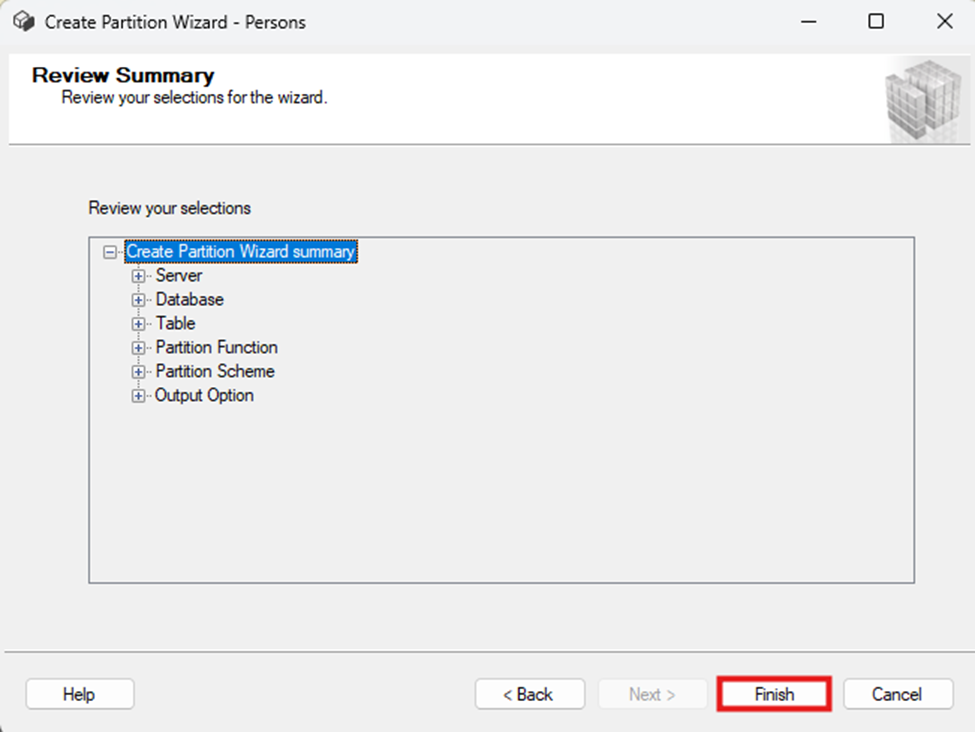
- در این مرحله اسکریپ کارهایی که می خواهیم انجام دهیم را خواهیم دید. با اجرای این اسکریپت جدول شما پارتیشن خواهد شد.
مطابق کوئری زیر از Rang Left استفاده شده است. به کدهای زیر دقت کنید.
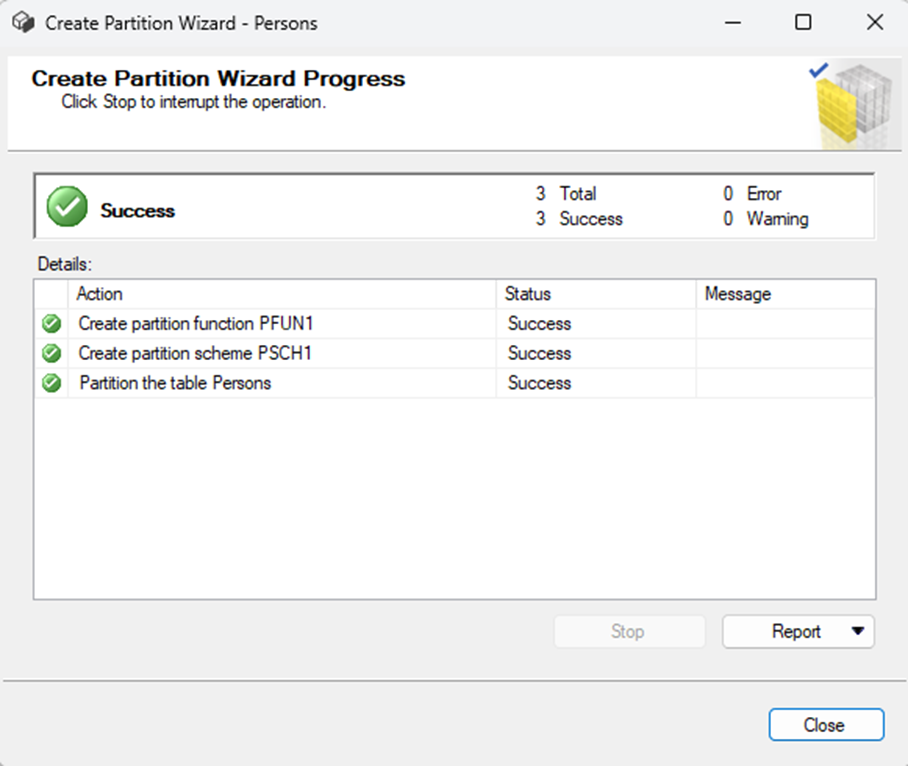

ایندکس گذاری (Index) روی جداول در Sql Server
مزیت ایندکس:
افزایش قابل توجه سرعت کوئری های select.
معایب ایندکس:
کاهش سرعت کوئری های insert و update.
اشغال بیشتر فضای حافظه.
انواع ایندکس:
- ایندکس index (برای افزایش سرعت در جستجوی مقدار)
- ایندکس unique (علاوه بر افزایش سرعت در جستجوی مقدار، یکتا بودن مقدار ستون رو هم چک می کند)
- ایندکس full-text (برای افزایش سرعت در جستجوی مقدارهایی از جنس متون نسبتا طولانی)
- ایندکس spatial (برای افزایش سرعت در جستجوی مقدارهایی از جنس موقعیت های مکانی)
- ایندکس primary (کلید اصلی جدول هست و علاوه بر جلوگیری از ورود مقدار تکراری از ورود null ها هم جلوگیری میکند)
نحوه ایجاد ایندکس روی جدول در Sql Server
جدول مورد نظر را که میخواهید روی آن ایندکس ایجاد کنید را انتخاب کنید و آن را باز کنید تا پوشه Indexes را مشاهده کنید.
روی Indexes کلیک راست کنید و گزینه New Index و Non Clustred Index را انتخاب کنید.
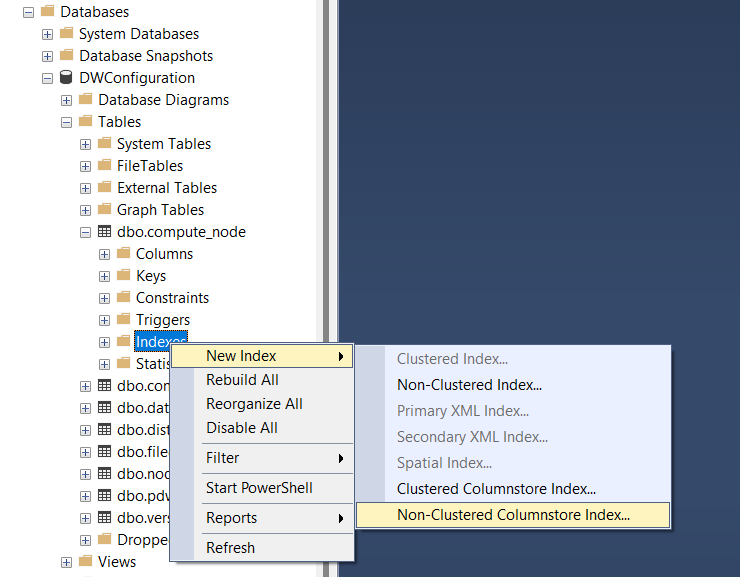
فرم New Index باز می شود. در این فرم باید مشخصات ایندکسی را که میخواهیم ایجاد کنیم تعیین کنیم. به تصویر زیر دقت کنید
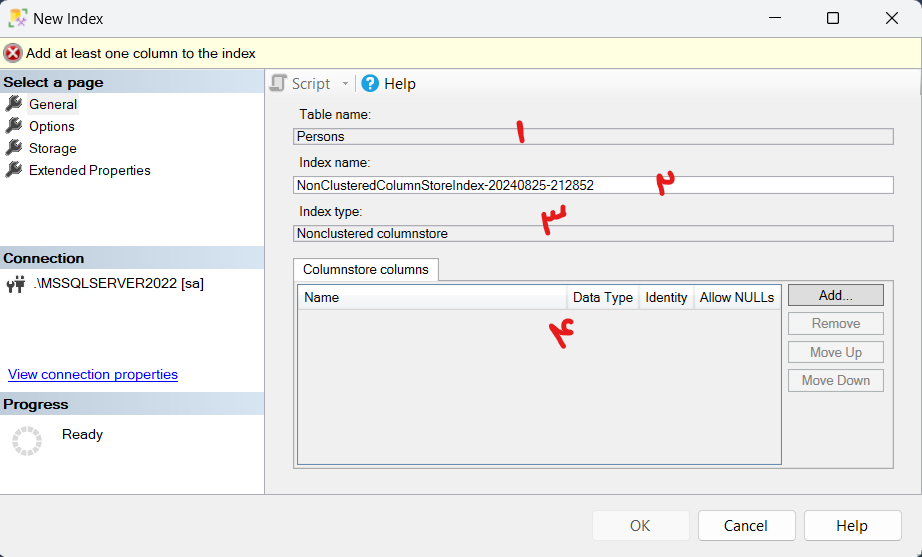
در قسمت شماره 1 نام جدولی که قرار است بر روی یک یا چند فیلد آن ایندکس گذاری شود نمایش داده می شود.
در قسمت شماره 2 باید نام ایندکس را مشخص کنید. دقت کنید که ایندکس آبجکت ها یا اشیای دیتابیس محسوب می شوند و باید نام منحصر بفرد داشته باشند. یعنی شما نمی توانید در یک دیتابیس 2 ایندکس هم نام داشته باشید.
در قسمت شماره 3 نوع ایندکس مشخص می شود که non clustred می باشد.
و در قسمت شماره 4 هم ستون یا ستون هایی که قرار است درگیر این ایندکس باشند مشخص می شود.
خب روی دکمه Add کلیک کنید تا یک ایندکس جدید ایجاد کنیم. فرم Select Column باز می شود. در این فرم باید ستون یا ستون هایی را که می خواهید روی آنها ایندکس ایجاد شود را انتخاب کنید.
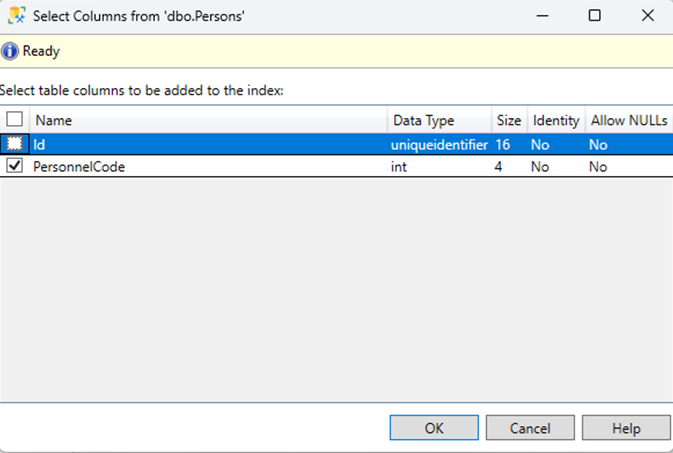
روی دکمه Ok کلیک کنید تا به فرم قبل برگردید. حالا ستون هایی که قرار است ایندکس گذاری شود مشخص شده است.
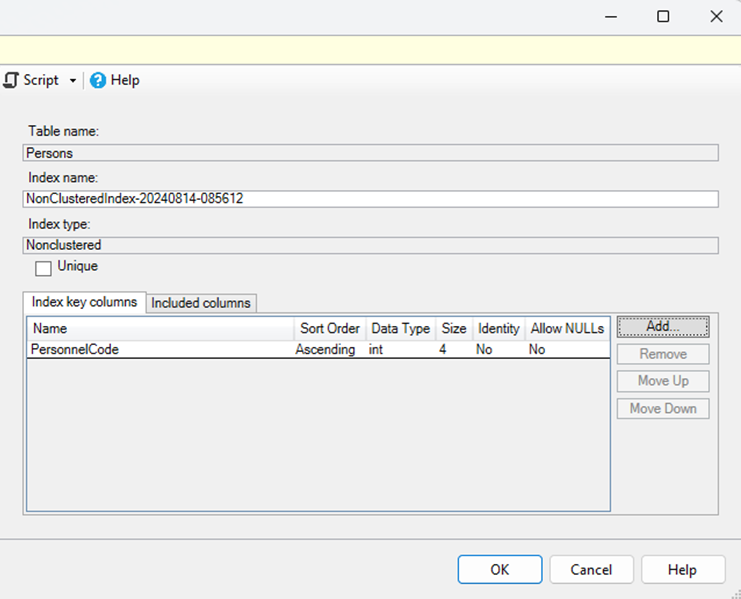
روی دکمه Ok کلیک کنید تا ایندکس شما ایجاد شود. حالا ایندکس شما باید در لیست ایندکس های جدول شما نمایش داده شود.
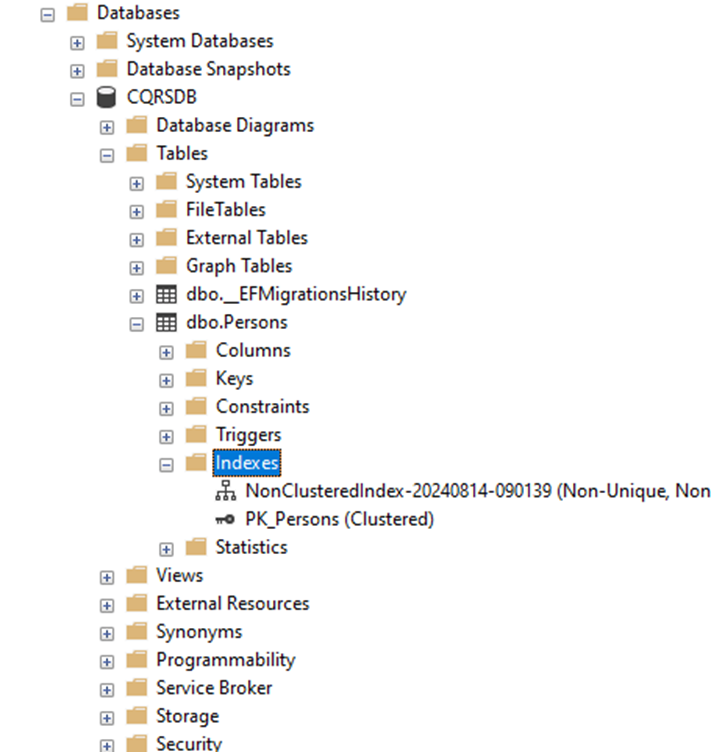
خب به این ترتیب شما موفق به ایجاد یک ایندکس non Clustered بر روی جدول خود شده اید.
معیارهای ایندکس گذاری بر روی جداول در Sql Server :
خب سوال اساسی اینجاست که چگونه تشخیص دهیم که یک جدول نیاز به ایندکس گذاری دارد یا خیر! و اگر نیاز به ایندکس گذاری دارد کدام ستون ها را برای ایندکس گذاری انتخاب کنیم. جهت ایجاد ایندکس بر روی جداول و همچنین انتخاب ستونهای ایندکس به نکات زیر توجه کنید.
معمولا بر روی جداولی باید ایندکس گذاری انجام شود که تعداد ستون های آنها زیاد می باشد.
معمولا بر روی جداولی باید ایندکس گذاری انجام شود که تعداد رکورهای خیلی زیادی دارد.
سعی کنید بر روی جداولی ایندکس گذاری کنید که تراکنش های زیادی در آن جدول انجام می شود. به عنوان مثال ممکن است جدولی تعداد ستون و ردیف زیادی هم داشته باشد ولی در روز یکی دو بار بیشتر از آن جدول استفاده نشود.
برای ایندکس گذاری فیلدهایی را انتخاب کنید که بیشتر مورد جستجو قرار می گیرند.
تا حد ممکن سعی کنید ایندکس گذاری بر روی یک فیلد انجام شود. مثلا از انتخاب چند فیلد در یک جدول ترجیحا خود داری نمایید.
اگر می خواهید ایندکس بر روی بیش از یک فیلد قرار دهید 2 فیلد هم نوع و مشابه باشند. به عنوان مثال ایندکس بر روی “نام کالا” و “توضیحات کالا” می تواند مناسب باشد.مثلا بر روی نام کالا و قیمت کالا یک ایندکس مشترک ایجاد کنیم که نام و قیمت هم نوع نیستند. بنابراین این ایندکس زیاد مناسب نیست.
انواع ایندکس در Sql Server :
به طور کلی دو نوع ایندکس در جداول می توان ایجاد کرد.
Clustred Index : این ایندکس به صورت اتوماتیک بر روی همه جداول و بر اساس کلید اصلی ایجاد می شود.
Non Clustred Index : این ایندکس ها را طراح دیتابیس با توجه به نیاز می تواند ایجاد کند.
ساخت API در Asp.net core با GraphQl و Sqlite
- ایجاد پروژه جدید : ابتدا یک پروژه جدید ASP.NET Core Web API ایجاد کنید:
پس از ایجاد
یک پوشه جدید با نام Data ایجاد میکنیم که می خواهیم تمام کدهای مربوط به پایگاه داده خود را در آن قرار دهیم.
- ایجاد مدل Speaker.cs در پوشه Data :
با استفاده از کد زیر یک فایل جدید Speaker.cs در دایرکتوری Data اضافه کنید :
using System.ComponentModel.DataAnnotations;
namespace ConferencePlanner.GraphQL.Data
{
public class Speaker
{
public int Id { get; set; }
[Required]
[StringLength(200)]
public string Name { get; set; }
[StringLength(4000)]
public string Bio { get; set; }
[StringLength(1000)]
public virtual string WebSite { get; set; }
}
}- پیکر بندی Sqlite :
- پکیج های زیر از NuGet دریافت و نصب میکنیم :
Microsoft.EntityFrameworkCore.Sqlite
Microsoft.EntityFrameworkCore.Tools- یک Entity Framework DbContext جدید با نام کلاس ApplicationDbContext.cs در پوشه Data ایجاد میکنیم:
using Microsoft.EntityFrameworkCore;
namespace ConferencePlanner.GraphQL.Data
{
public class ApplicationDbContext : DbContext
{
public ApplicationDbContext(DbContextOptions<ApplicationDbContext> options)
: base(options)
{
}
public DbSet<Speaker> Speakers { get; set; }
}
}- پیکر بندی Startup.cs :
در Startup.cs خط کد زیر را به سرویس ها اضافه میکنیم
services.AddDbContext<ApplicationDbContext>(options => options.UseSqlite("Data Source=conferences.db"));- پیکر بندی EF Migrations :
در Visual Studio، Tools -> NuGet Package Manager -> Package Manager Console را انتخاب کنید.
دستورات زیر را جهت Migration و آپدیت دیتابیس در Package Manager Console اجرا کنید
Add-Migration Initial
Update-Database- اضافه کردن GraphQL :
- پکیج زیر را از NuGet دریافت نمایید:
HotChocolate.AspNetCore- در مرحله بعد ما نوع ریشه پرس و جو خود ( Query.cs) را در پوشه Data ایجاد می کنیم و resolver اضافه می کنیم که همه speakers ما را واکشی کند.
using System.Linq;
using HotChocolate;
using ConferencePlanner.GraphQL.Data;
namespace ConferencePlanner.GraphQL
{
public class Query
{
public IQueryable<Speaker> GetSpeakers([Service] ApplicationDbContext context) =>
context.Speakers;
}
}- قبل از اینکه بتوانیم کاری با نوع ریشه پرس و جو خود انجام دهیم، باید GraphQL را راه اندازی کنیم و نوع ریشه پرس و جو خود را ثبت کنیم. کد زیر را در متد Startup.cs اضافه کنید.
services
.AddGraphQLServer()
.AddQueryType<Query>();- در مرحله بعد باید میان افزار GraphQL خود را پیکربندی کنیم تا سرور بداند که چگونه درخواست های GraphQL را اجرا کند. برای این کار app.UseEndpoints…کد زیر را در Startup.cs اضافه میکنیم.
app.UseEndpoints(endpoints =>
{
endpoints.MapGraphQL();
});
اکنون Startup.cs ما باید به این شکل باشد.
using ASPNetCoreGraphQL.GraphQl;
using ASPNetCoreGraphQL.GraphQl.Data;
using Microsoft.EntityFrameworkCore;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddDbContext<ApplicationDbContext>(options => options.UseSqlite("Data Source=conferences.db"));
builder.Services
.AddGraphQLServer()
.AddQueryType<Query>()
.AddMutationType<Mutation>(); ;
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseRouting();
app.UseEndpoints(endpoints =>
{
endpoints.MapGraphQL();
});
app.Run();حال پروژه را اجرا نمایید و می بایست بعد از ورود به آدرس زیر پروژه ذیل نمایش داده شود.
https://localhost:7266/graphql
برای بررسی نوع برگشتی فیلد speakers ، روی schema explorer کلیک کنید و روی فیلد speakers کلیک کنید .
توجه: ممکن است مجبور شوید طرح را دوباره بارگیری کنید، می توانید این کار را با کلیک کردن روی دکمه refresh در گوشه سمت راست بالا انجام دهید.
- اضافه کردن Mutation :
بنابراین، تا کنون نوع ریشه Query را به طرح خود اضافه کردهایم که به ما امکان میدهد از speakers پرس و جو کنیم. با این حال، در این مرحله، هیچ راهی برای افزودن یا تغییر داده وجود ندارد. در این بخش قصد داریم تا نوع root Mutation را اضافه کنیم تا speakers جدیدی به پایگاه داده خود اضافه کنیم.
برای Mutation از الگوی Relay Mutation استفاده میکنیم که معمولاً در GraphQL استفاده میشود.
یک جهش از سه جزء تشکیل شده است، Input ، Payload و خود Mutation
در این مورد ما می خواهیم یک Mutation به نام ایجاد کنیم addSpeaker، طبق قرارداد، جهش ها به عنوان فعل نامگذاری می شوند، ورودی های آنها نامی است که در انتها “Input” ضمیمه شده است، و آنها یک شی است که نام آن با “Payload” اضافه شده است.
بنابراین، برای addSpeakerجهش خود، دو نوع ایجاد می کنیم AddSpeakerInput و AddSpeakerPayload :
- AddSpeakerInput.csبا کد زیر یک فایل به پروژه خود اضافه کنید :
namespace ConferencePlanner.GraphQL
{
public record AddSpeakerInput(
string Name,
string Bio,
string WebSite);
}ورودی و خروجی (بارگذاری بار) هر دو حاوی یک شناسه جهش مشتری هستند که برای تطبیق درخواست ها و پاسخ ها در برخی از چارچوب های مشتری استفاده می شود.
- سپس ما را اضافه می کنیم
AddSpeakerPayloadکه خروجی جهش GraphQL ما را با افزودن کد زیر نشان می دهد:
using ConferencePlanner.GraphQL.Data;
namespace ConferencePlanner.GraphQL
{
public class AddSpeakerPayload
{
public AddSpeakerPayload(Speaker speaker)
{
Speaker = speaker;
}
public Speaker Speaker { get; }
}
}- حالا بیایید نوع جهش واقعی را با
addSpeakerجهش خود در آن اضافه کنیم.
using System.Threading.Tasks;
using ConferencePlanner.GraphQL.Data;
using HotChocolate;
namespace ConferencePlanner.GraphQL
{
public class Mutation
{
public async Task<AddSpeakerPayload> AddSpeakerAsync(
AddSpeakerInput input,
[Service] ApplicationDbContext context)
{
var speaker = new Speaker
{
Name = input.Name,
Bio = input.Bio,
WebSite = input.WebSite
};
context.Speakers.Add(speaker);
await context.SaveChangesAsync();
return new AddSpeakerPayload(speaker);
}
}
}- حال در program.cs باید
Mutation
services
.AddGraphQLServer()
.AddQueryType<Query>()
.AddMutationType<Mutation>();- تست خروجی :
- اکنون باید یک نوع Query به نام Speacker و یک Mutation به نام addSpeaker وجود داشته باشد.
- سپس با نوشتن یک جهش GraphQL یک Speaker اضافه کنید.
mutation AddSpeaker {
addSpeaker(input: {
name: "Speaker Name"
bio: "Speaker Bio"
webSite: "http://speaker.website" }) {
speaker {
id
}
}
}
- نام همه Speackers پایگاه داده را جویا شوید.
query GetSpeakerNames {
speakers {
name
}
}
- سورس کد پروژه در آدرس ذیل قابل دریافت می باشد :